if (!$mask) { file_put_contents($pathname, $message . "\n", FILE_APPEND);
file_put_contents - [internal], line ??
Cake\Log\Engine\FileLog::log() - CORE/src/Log/Engine/FileLog.php, line 140
Cake\Log\Log::write() - CORE/src/Log/Log.php, line 392
Cake\Log\Log::warning() - CORE/src/Log/Log.php, line 477
DebugKit\ToolbarService::isSuspiciouslyProduction() - ROOT/vendor/cakephp/debug_kit/src/ToolbarService.php, line 169
DebugKit\ToolbarService::isEnabled() - ROOT/vendor/cakephp/debug_kit/src/ToolbarService.php, line 105
DebugKit\Plugin::bootstrap() - ROOT/vendor/cakephp/debug_kit/src/Plugin.php, line 48
Cake\Http\BaseApplication::pluginBootstrap() - CORE/src/Http/BaseApplication.php, line 182
Cake\Http\Server::bootstrap() - CORE/src/Http/Server.php, line 111
Cake\Http\Server::run() - CORE/src/Http/Server.php, line 79
[main] - ROOT/webroot/index.php, line 40
Notice: file_put_contents() [function.file-put-contents]: Write of 1108 bytes failed with errno=28 No space left on device in /www/wwwroot/www.adminso.com/vendor/cakephp/cakephp/src/Log/Engine/FileLog.php on line 140
Notice (8): SplFileObject::fwrite() [<a href='https://secure.php.net/splfileobject.fwrite'>splfileobject.fwrite</a>]: Write of 7651 bytes failed with errno=28 No space left on device [CORE/src/Cache/Engine/FileEngine.php, line 141]
SplFileObject::fwrite() - [internal], line ??
Cake\Cache\Engine\FileEngine::set() - CORE/src/Cache/Engine/FileEngine.php, line 141
Cake\I18n\TranslatorRegistry::get() - CORE/src/I18n/TranslatorRegistry.php, line 206
Cake\I18n\I18n::getTranslator() - CORE/src/I18n/I18n.php, line 148
__ - CORE/src/I18n/functions.php, line 45
App\Controller\NewsController::view() - APP/Controller/NewsController.php, line 3420
Cake\Controller\Controller::invokeAction() - CORE/src/Controller/Controller.php, line 539
Cake\Controller\ControllerFactory::handle() - CORE/src/Controller/ControllerFactory.php, line 140
Cake\Controller\ControllerFactory::invoke() - CORE/src/Controller/ControllerFactory.php, line 115
Cake\Http\BaseApplication::handle() - CORE/src/Http/BaseApplication.php, line 317
Cake\Http\Runner::handle() - CORE/src/Http/Runner.php, line 77
Cake\Http\Middleware\CsrfProtectionMiddleware::process() - CORE/src/Http/Middleware/CsrfProtectionMiddleware.php, line 164
Cake\Http\Runner::handle() - CORE/src/Http/Runner.php, line 73
Cake\I18n\Middleware\LocaleSelectorMiddleware::process() - CORE/src/I18n/Middleware/LocaleSelectorMiddleware.php, line 61
Cake\Http\Runner::handle() - CORE/src/Http/Runner.php, line 73
Cake\Http\Middleware\BodyParserMiddleware::process() - CORE/src/Http/Middleware/BodyParserMiddleware.php, line 157
Cake\Http\Runner::handle() - CORE/src/Http/Runner.php, line 73
Notice: file_put_contents() [function.file-put-contents]: Write of 2560 bytes failed with errno=28 No space left on device in /www/wwwroot/www.adminso.com/vendor/cakephp/cakephp/src/Log/Engine/FileLog.php on line 140
Notice (8): SplFileObject::fwrite() [<a href='https://secure.php.net/splfileobject.fwrite'>splfileobject.fwrite</a>]: Write of 3642 bytes failed with errno=28 No space left on device [CORE/src/Cache/Engine/FileEngine.php, line 141]
SplFileObject::fwrite() - [internal], line ??
Cake\Cache\Engine\FileEngine::set() - CORE/src/Cache/Engine/FileEngine.php, line 141
Cake\Database\Schema\CachedCollection::describe() - CORE/src/Database/Schema/CachedCollection.php, line 85
Cake\ORM\Table::getSchema() - CORE/src/ORM/Table.php, line 513
Cake\ORM\Table::getPrimaryKey() - CORE/src/ORM/Table.php, line 653
Cake\ORM\Query::_addAssociationsToTypeMap() - CORE/src/ORM/Query.php, line 507
Cake\ORM\Query::contain() - CORE/src/ORM/Query.php, line 462
App\Controller\NewsController::action_() - APP/Controller/NewsController.php, line 6433
App\Controller\NewsController::get_data() - APP/Controller/NewsController.php, line 5701
App\Controller\NewsController::action_cache() - APP/Controller/NewsController.php, line 5625
App\Controller\NewsController::cache_action() - APP/Controller/NewsController.php, line 5281
App\Controller\NewsController::view() - APP/Controller/NewsController.php, line 3436
Cake\Controller\Controller::invokeAction() - CORE/src/Controller/Controller.php, line 539
Cake\Controller\ControllerFactory::handle() - CORE/src/Controller/ControllerFactory.php, line 140
Cake\Controller\ControllerFactory::invoke() - CORE/src/Controller/ControllerFactory.php, line 115
Cake\Http\BaseApplication::handle() - CORE/src/Http/BaseApplication.php, line 317
Cake\Http\Runner::handle() - CORE/src/Http/Runner.php, line 77
Notice: file_put_contents() [function.file-put-contents]: Write of 3106 bytes failed with errno=28 No space left on device in /www/wwwroot/www.adminso.com/vendor/cakephp/cakephp/src/Log/Engine/FileLog.php on line 140
Notice (8): SplFileObject::fwrite() [<a href='https://secure.php.net/splfileobject.fwrite'>splfileobject.fwrite</a>]: Write of 920 bytes failed with errno=28 No space left on device [CORE/src/Cache/Engine/FileEngine.php, line 141]
SplFileObject::fwrite() - [internal], line ??
Cake\Cache\Engine\FileEngine::set() - CORE/src/Cache/Engine/FileEngine.php, line 141
Cake\Database\Schema\CachedCollection::describe() - CORE/src/Database/Schema/CachedCollection.php, line 85
Cake\ORM\Table::getSchema() - CORE/src/ORM/Table.php, line 513
Cake\ORM\Query::addDefaultTypes() - CORE/src/ORM/Query.php, line 290
Cake\ORM\Query::__construct() - CORE/src/ORM/Query.php, line 184
Cake\ORM\Table::query() - CORE/src/ORM/Table.php, line 1702
Cake\ORM\Table::find() - CORE/src/ORM/Table.php, line 1263
App\Controller\NewsController::action_() - APP/Controller/NewsController.php, line 6539
App\Controller\NewsController::get_data() - APP/Controller/NewsController.php, line 5701
App\Controller\NewsController::action_cache() - APP/Controller/NewsController.php, line 5625
App\Controller\NewsController::cache_action() - APP/Controller/NewsController.php, line 5281
App\Controller\NewsController::view() - APP/Controller/NewsController.php, line 3436
Cake\Controller\Controller::invokeAction() - CORE/src/Controller/Controller.php, line 539
Cake\Controller\ControllerFactory::handle() - CORE/src/Controller/ControllerFactory.php, line 140
Cake\Controller\ControllerFactory::invoke() - CORE/src/Controller/ControllerFactory.php, line 115
Cake\Http\BaseApplication::handle() - CORE/src/Http/BaseApplication.php, line 317
Notice: file_put_contents() [function.file-put-contents]: Write of 3151 bytes failed with errno=28 No space left on device in /www/wwwroot/www.adminso.com/vendor/cakephp/cakephp/src/Log/Engine/FileLog.php on line 140
Notice (8): SplFileObject::fwrite() [<a href='https://secure.php.net/splfileobject.fwrite'>splfileobject.fwrite</a>]: Write of 173 bytes failed with errno=28 No space left on device [CORE/src/Cache/Engine/FileEngine.php, line 141]
SplFileObject::fwrite() - [internal], line ??
Cake\Cache\Engine\FileEngine::set() - CORE/src/Cache/Engine/FileEngine.php, line 141
Cake\Cache\Cache::write() - CORE/src/Cache/Cache.php, line 266
App\Controller\NewsController::action_() - APP/Controller/NewsController.php, line 6766
App\Controller\NewsController::get_data() - APP/Controller/NewsController.php, line 5701
App\Controller\NewsController::action_cache() - APP/Controller/NewsController.php, line 5625
App\Controller\NewsController::cache_action() - APP/Controller/NewsController.php, line 5281
App\Controller\NewsController::view() - APP/Controller/NewsController.php, line 3634
Cake\Controller\Controller::invokeAction() - CORE/src/Controller/Controller.php, line 539
Cake\Controller\ControllerFactory::handle() - CORE/src/Controller/ControllerFactory.php, line 140
Cake\Controller\ControllerFactory::invoke() - CORE/src/Controller/ControllerFactory.php, line 115
Cake\Http\BaseApplication::handle() - CORE/src/Http/BaseApplication.php, line 317
Cake\Http\Runner::handle() - CORE/src/Http/Runner.php, line 77
Cake\Http\Middleware\CsrfProtectionMiddleware::process() - CORE/src/Http/Middleware/CsrfProtectionMiddleware.php, line 164
Cake\Http\Runner::handle() - CORE/src/Http/Runner.php, line 73
Cake\I18n\Middleware\LocaleSelectorMiddleware::process() - CORE/src/I18n/Middleware/LocaleSelectorMiddleware.php, line 61
Cake\Http\Runner::handle() - CORE/src/Http/Runner.php, line 73
Notice: file_put_contents() [function.file-put-contents]: Write of 2791 bytes failed with errno=28 No space left on device in /www/wwwroot/www.adminso.com/vendor/cakephp/cakephp/src/Log/Engine/FileLog.php on line 140
Warning (512): long cache was unable to write 'b9c658291aa55313747b564f9d71176a' to Cake\Cache\Engine\FileEngine cache [CORE/src/Cache/Cache.php, line 275]
Cake\Cache\Cache::write() - CORE/src/Cache/Cache.php, line 275
App\Controller\NewsController::action_() - APP/Controller/NewsController.php, line 6766
App\Controller\NewsController::get_data() - APP/Controller/NewsController.php, line 5701
App\Controller\NewsController::action_cache() - APP/Controller/NewsController.php, line 5625
App\Controller\NewsController::cache_action() - APP/Controller/NewsController.php, line 5281
App\Controller\NewsController::view() - APP/Controller/NewsController.php, line 3634
Cake\Controller\Controller::invokeAction() - CORE/src/Controller/Controller.php, line 539
Cake\Controller\ControllerFactory::handle() - CORE/src/Controller/ControllerFactory.php, line 140
Cake\Controller\ControllerFactory::invoke() - CORE/src/Controller/ControllerFactory.php, line 115
Cake\Http\BaseApplication::handle() - CORE/src/Http/BaseApplication.php, line 317
Cake\Http\Runner::handle() - CORE/src/Http/Runner.php, line 77
Cake\Http\Middleware\CsrfProtectionMiddleware::process() - CORE/src/Http/Middleware/CsrfProtectionMiddleware.php, line 164
Cake\Http\Runner::handle() - CORE/src/Http/Runner.php, line 73
Cake\I18n\Middleware\LocaleSelectorMiddleware::process() - CORE/src/I18n/Middleware/LocaleSelectorMiddleware.php, line 61
Cake\Http\Runner::handle() - CORE/src/Http/Runner.php, line 73
Cake\Http\Middleware\BodyParserMiddleware::process() - CORE/src/Http/Middleware/BodyParserMiddleware.php, line 157
Notice: file_put_contents() [function.file-put-contents]: Write of 2586 bytes failed with errno=28 No space left on device in /www/wwwroot/www.adminso.com/vendor/cakephp/cakephp/src/Log/Engine/FileLog.php on line 140
Notice (8): SplFileObject::fwrite() [<a href='https://secure.php.net/splfileobject.fwrite'>splfileobject.fwrite</a>]: Write of 174 bytes failed with errno=28 No space left on device [CORE/src/Cache/Engine/FileEngine.php, line 141]
SplFileObject::fwrite() - [internal], line ??
Cake\Cache\Engine\FileEngine::set() - CORE/src/Cache/Engine/FileEngine.php, line 141
Cake\Cache\Cache::write() - CORE/src/Cache/Cache.php, line 266
App\Controller\NewsController::action_() - APP/Controller/NewsController.php, line 6766
App\Controller\NewsController::get_data() - APP/Controller/NewsController.php, line 5701
App\Controller\NewsController::action_cache() - APP/Controller/NewsController.php, line 5625
App\Controller\NewsController::cache_action() - APP/Controller/NewsController.php, line 5281
App\Controller\NewsController::view() - APP/Controller/NewsController.php, line 3663
Cake\Controller\Controller::invokeAction() - CORE/src/Controller/Controller.php, line 539
Cake\Controller\ControllerFactory::handle() - CORE/src/Controller/ControllerFactory.php, line 140
Cake\Controller\ControllerFactory::invoke() - CORE/src/Controller/ControllerFactory.php, line 115
Cake\Http\BaseApplication::handle() - CORE/src/Http/BaseApplication.php, line 317
Cake\Http\Runner::handle() - CORE/src/Http/Runner.php, line 77
Cake\Http\Middleware\CsrfProtectionMiddleware::process() - CORE/src/Http/Middleware/CsrfProtectionMiddleware.php, line 164
Cake\Http\Runner::handle() - CORE/src/Http/Runner.php, line 73
Cake\I18n\Middleware\LocaleSelectorMiddleware::process() - CORE/src/I18n/Middleware/LocaleSelectorMiddleware.php, line 61
Cake\Http\Runner::handle() - CORE/src/Http/Runner.php, line 73
Notice: file_put_contents() [function.file-put-contents]: Write of 2791 bytes failed with errno=28 No space left on device in /www/wwwroot/www.adminso.com/vendor/cakephp/cakephp/src/Log/Engine/FileLog.php on line 140
Warning (512): long cache was unable to write 'b7ca207b9a9d189ca8a90336731943e5' to Cake\Cache\Engine\FileEngine cache [CORE/src/Cache/Cache.php, line 275]
Cake\Cache\Cache::write() - CORE/src/Cache/Cache.php, line 275
App\Controller\NewsController::action_() - APP/Controller/NewsController.php, line 6766
App\Controller\NewsController::get_data() - APP/Controller/NewsController.php, line 5701
App\Controller\NewsController::action_cache() - APP/Controller/NewsController.php, line 5625
App\Controller\NewsController::cache_action() - APP/Controller/NewsController.php, line 5281
App\Controller\NewsController::view() - APP/Controller/NewsController.php, line 3663
Cake\Controller\Controller::invokeAction() - CORE/src/Controller/Controller.php, line 539
Cake\Controller\ControllerFactory::handle() - CORE/src/Controller/ControllerFactory.php, line 140
Cake\Controller\ControllerFactory::invoke() - CORE/src/Controller/ControllerFactory.php, line 115
Cake\Http\BaseApplication::handle() - CORE/src/Http/BaseApplication.php, line 317
Cake\Http\Runner::handle() - CORE/src/Http/Runner.php, line 77
Cake\Http\Middleware\CsrfProtectionMiddleware::process() - CORE/src/Http/Middleware/CsrfProtectionMiddleware.php, line 164
Cake\Http\Runner::handle() - CORE/src/Http/Runner.php, line 73
Cake\I18n\Middleware\LocaleSelectorMiddleware::process() - CORE/src/I18n/Middleware/LocaleSelectorMiddleware.php, line 61
Cake\Http\Runner::handle() - CORE/src/Http/Runner.php, line 73
Cake\Http\Middleware\BodyParserMiddleware::process() - CORE/src/Http/Middleware/BodyParserMiddleware.php, line 157
Notice: file_put_contents() [function.file-put-contents]: Write of 2586 bytes failed with errno=28 No space left on device in /www/wwwroot/www.adminso.com/vendor/cakephp/cakephp/src/Log/Engine/FileLog.php on line 140
Notice (8): unserialize() [<a href='https://secure.php.net/function.unserialize'>function.unserialize</a>]: Error at offset 24562 of 24565 bytes [APP/Controller/NewsController.php, line 5571]
unserialize - [internal], line ??
App\Controller\NewsController::action_cache() - APP/Controller/NewsController.php, line 5571
App\Controller\NewsController::cache_action() - APP/Controller/NewsController.php, line 5281
App\Controller\NewsController::view() - APP/Controller/NewsController.php, line 3698
Cake\Controller\Controller::invokeAction() - CORE/src/Controller/Controller.php, line 539
Cake\Controller\ControllerFactory::handle() - CORE/src/Controller/ControllerFactory.php, line 140
Cake\Controller\ControllerFactory::invoke() - CORE/src/Controller/ControllerFactory.php, line 115
Cake\Http\BaseApplication::handle() - CORE/src/Http/BaseApplication.php, line 317
Cake\Http\Runner::handle() - CORE/src/Http/Runner.php, line 77
Cake\Http\Middleware\CsrfProtectionMiddleware::process() - CORE/src/Http/Middleware/CsrfProtectionMiddleware.php, line 164
Cake\Http\Runner::handle() - CORE/src/Http/Runner.php, line 73
Cake\I18n\Middleware\LocaleSelectorMiddleware::process() - CORE/src/I18n/Middleware/LocaleSelectorMiddleware.php, line 61
Cake\Http\Runner::handle() - CORE/src/Http/Runner.php, line 73
Cake\Http\Middleware\BodyParserMiddleware::process() - CORE/src/Http/Middleware/BodyParserMiddleware.php, line 157
Cake\Http\Runner::handle() - CORE/src/Http/Runner.php, line 73
Cake\Routing\Middleware\RoutingMiddleware::process() - CORE/src/Routing/Middleware/RoutingMiddleware.php, line 161
Cake\Http\Runner::handle() - CORE/src/Http/Runner.php, line 73
Notice: file_put_contents() [function.file-put-contents]: Write of 2397 bytes failed with errno=28 No space left on device in /www/wwwroot/www.adminso.com/vendor/cakephp/cakephp/src/Log/Engine/FileLog.php on line 140
Notice (8): unserialize() [<a href='https://secure.php.net/function.unserialize'>function.unserialize</a>]: Error at offset 90091 of 90101 bytes [APP/Controller/NewsController.php, line 5571]
unserialize - [internal], line ??
App\Controller\NewsController::action_cache() - APP/Controller/NewsController.php, line 5571
App\Controller\NewsController::cache_action() - APP/Controller/NewsController.php, line 5281
App\Controller\NewsController::article_show() - APP/Controller/NewsController.php, line 4290
App\Controller\NewsController::view() - APP/Controller/NewsController.php, line 3822
Cake\Controller\Controller::invokeAction() - CORE/src/Controller/Controller.php, line 539
Cake\Controller\ControllerFactory::handle() - CORE/src/Controller/ControllerFactory.php, line 140
Cake\Controller\ControllerFactory::invoke() - CORE/src/Controller/ControllerFactory.php, line 115
Cake\Http\BaseApplication::handle() - CORE/src/Http/BaseApplication.php, line 317
Cake\Http\Runner::handle() - CORE/src/Http/Runner.php, line 77
Cake\Http\Middleware\CsrfProtectionMiddleware::process() - CORE/src/Http/Middleware/CsrfProtectionMiddleware.php, line 164
Cake\Http\Runner::handle() - CORE/src/Http/Runner.php, line 73
Cake\I18n\Middleware\LocaleSelectorMiddleware::process() - CORE/src/I18n/Middleware/LocaleSelectorMiddleware.php, line 61
Cake\Http\Runner::handle() - CORE/src/Http/Runner.php, line 73
Cake\Http\Middleware\BodyParserMiddleware::process() - CORE/src/Http/Middleware/BodyParserMiddleware.php, line 157
Cake\Http\Runner::handle() - CORE/src/Http/Runner.php, line 73
Cake\Routing\Middleware\RoutingMiddleware::process() - CORE/src/Routing/Middleware/RoutingMiddleware.php, line 161
Notice: file_put_contents() [function.file-put-contents]: Write of 2490 bytes failed with errno=28 No space left on device in /www/wwwroot/www.adminso.com/vendor/cakephp/cakephp/src/Log/Engine/FileLog.php on line 140 Multi modal large model illusion reduced by 30%! China University of Science and Technology and others proposed the first illusion correction architecture "Woodpecker" woodpecker - AdminSo
Multi modal large model illusion reduced by 30%! China University of Science and Technology and others proposed the first illusion correction architecture "Woodpecker" woodpecker
Xinzhiyuan ReportEditor: So sleepyIntroduction to New Intelligence ElementRecently, researchers from institutions such as China University of Science and Technology have proposed the first multimodal modification architecture, "Woodpecker," which can effectively solve the problem of MLLM output hallucinations.Visual hallucination is a typical problem commonly encountered in multimodal large language models (MLLMs)
Xinzhiyuan Report
Editor: So sleepy
Introduction to New Intelligence ElementRecently, researchers from institutions such as China University of Science and Technology have proposed the first multimodal modification architecture, "Woodpecker," which can effectively solve the problem of MLLM output hallucinations.
Visual hallucination is a typical problem commonly encountered in multimodal large language models (MLLMs).
Simply put, the description output by the model does not match the image content.
The following image shows two types of illusions, with the red part mistakenly describing the dog's color (attribute illusion) and the blue part describing something that does not actually exist in the image (target illusion).
Hallucinations have a significant negative impact on the reliability of models, which has attracted the attention of many researchers.
The previous methods mainly focused on MLLM itself, by improving the training data and architecture to train a new MLLM through fine-tuning.
However, this approach incurs significant data construction and training costs, and is difficult to generalize to various existing MLLMs.
Recently, researchers from institutions such as China University of Science and Technology have proposed a universal plug-and-play architecture that does not require trainingWoodpeckerResolve the issue of MLLM output hallucinations through correction.
Paper address: https://arxiv.org/pdf/2310.16045.pdf
Specifically, Woodpicker can correct the illusion of model output in various scenarios and output detection boxes as citations to indicate the existence of corresponding targets.
For example, when faced with descriptive tasks, Woodpecker can correct the parts with hallucinations:
Woodpecker can also accurately correct small objects that are difficult to detect in MLLM:
Faced with complex counting scenarios that MLLM is difficult to solve, Woodpecker can also solve:
Woopecker also handles the illusion problem of target attribute classes well:
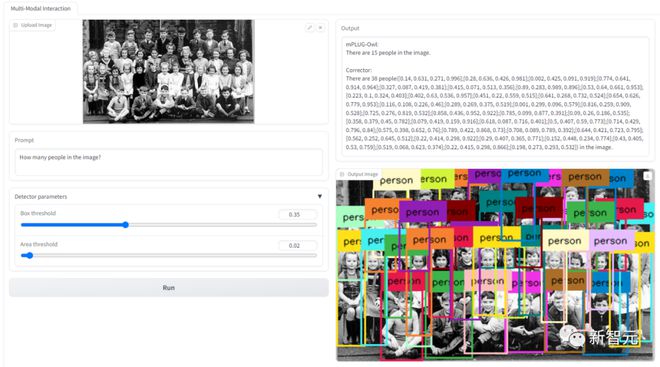
In addition, Woodpecker also provides Demos for readers to test and use.
As shown in the following figure, by uploading the image and entering the request, you can obtain the pre and post correction model responses, as well as new images for reference and verification.
method
The architecture of Woodpecker is as follows, which includes five main steps: key concept extraction, problem construction, visual knowledge verification, visual assertion generation, and illusion correction.
-Key Concept Extraction
The key concept refers to the existence targets that are most likely to have hallucinations in the output of MLLM, such as "bicycles; trash cans; people" described in the above image.
We can use the Prompt big language model to extract these key concepts, which are the foundation for subsequent steps.
-Problem Construction
Around the key concepts extracted in the previous step, the Prompt big language model is used to propose some questions that can help verify the authenticity of image descriptions, such as "How many bicycles are there in the picture?", "What is next to the trash can?", and so on.
-Visual knowledge testing
Use visual basic models to test the proposed questions and obtain information related to images and descriptive text.
For example, we can use GroundingDINO for object detection to determine whether key targets exist and the number of key targets. Because visual basic models such as GroundingDINO have a stronger ability to perceive images than MLLM itself.
For attribute questions such as target color, BLIP-2 can be used to answer them. Traditional VQA models such as BLIP-2 have limited length of output answers and fewer hallucination problems.
-Visual Assertion Generation
Based on the problems obtained in the first two steps and the corresponding visual information, synthesize a structured 'visual assertion'. These visual assertions can be seen as a visual knowledge base related to the original MLLM responses and input images.
-Hallucination correction
Based on the previous results, a large language model is used to modify the text output of MLLM one by one, and the detection box information corresponding to the target is provided as a reference for visual inspection.
experimental result
Several typical MLLMs were selected as baselines for the experiment, including LLaVA, mPLUG-Owl, Otter, and MiniGPT-4.
WoodpeckerPOPEexperimental result
The results indicate that applying Woodpecker correction on different MLLM results in varying degrees of improvement.
Under random setting, Woodpecker improved the accuracy indicators of MiniGPT-4 and mPLUG-Owl by 30.66% and 24.33%, respectively.
In addition, the researchers also applied a more comprehensive validation set MME to further test Woodpecker's ability to correct attribute hallucinations. The results are shown in the table below:
From the table, it can be seen that Woodpecker is not only effective in dealing with target hallucinations, but also has excellent performance in correcting color and other attribute hallucinations. The color score of LLaVA has significantly increased from 78.33 points to 155 points!
After Woodpecker correction, the total scores of the four baseline models on all four test subsets exceeded 500 points, indicating a significant improvement in overall perception ability.
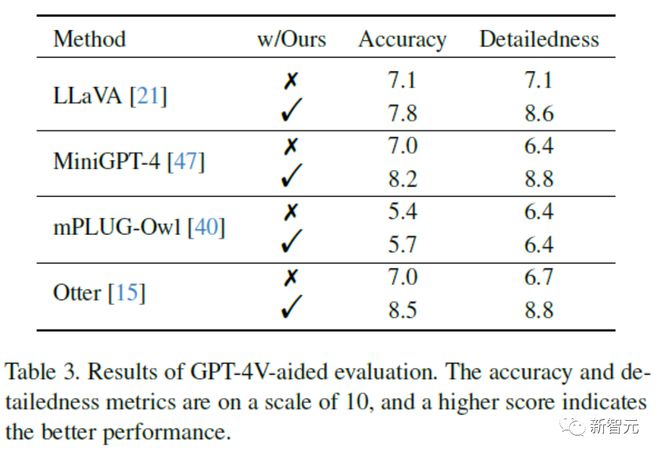
To measure correction performance more directly, a more direct approach is to use open evaluation.
Unlike the previous approach of translating images into plain text GPT-4, this article utilizes the recently opened visual interface of OpenAI and proposes using GPT-4 (Vision) to directly score the following two dimensions for pre and post correction image descriptions:
-Accuracy: Whether the model's response is accurate relative to the image content
-Level of detail: The richness of detail in the model response
experimental result :
The results indicate that the accuracy of image description has been improved after Woodpecker correction, indicating that the framework can effectively correct the hallucinations in the description.
On the other hand, the location information introduced by Woodpecker after modification enriches the text description and provides further location information, thereby improving the richness of details.
The GPT-4V assisted evaluation example is shown in the following figure:
Interested readers can read the paper to learn more about the content.
Disclaimer: The content of this article is sourced from the internet. The copyright of the text, images, and other materials belongs to the original author. The platform reprints the materials for the purpose of conveying more information. The content of the article is for reference and learning only, and should not be used for commercial purposes. If it infringes on your legitimate rights and interests, please contact us promptly and we will handle it as soon as possible! We respect copyright and are committed to protecting it. Thank you for sharing.