if (!$mask) { file_put_contents($pathname, $message . "\n", FILE_APPEND);
file_put_contents - [internal], line ??
Cake\Log\Engine\FileLog::log() - CORE/src/Log/Engine/FileLog.php, line 140
Cake\Log\Log::write() - CORE/src/Log/Log.php, line 392
Cake\Log\Log::warning() - CORE/src/Log/Log.php, line 477
DebugKit\ToolbarService::isSuspiciouslyProduction() - ROOT/vendor/cakephp/debug_kit/src/ToolbarService.php, line 169
DebugKit\ToolbarService::isEnabled() - ROOT/vendor/cakephp/debug_kit/src/ToolbarService.php, line 105
DebugKit\Plugin::bootstrap() - ROOT/vendor/cakephp/debug_kit/src/Plugin.php, line 48
Cake\Http\BaseApplication::pluginBootstrap() - CORE/src/Http/BaseApplication.php, line 182
Cake\Http\Server::bootstrap() - CORE/src/Http/Server.php, line 111
Cake\Http\Server::run() - CORE/src/Http/Server.php, line 79
[main] - ROOT/webroot/index.php, line 40
Notice: file_put_contents() [function.file-put-contents]: Write of 1108 bytes failed with errno=28 No space left on device in /www/wwwroot/www.adminso.com/vendor/cakephp/cakephp/src/Log/Engine/FileLog.php on line 140
Notice (8): SplFileObject::fwrite() [<a href='https://secure.php.net/splfileobject.fwrite'>splfileobject.fwrite</a>]: Write of 7651 bytes failed with errno=28 No space left on device [CORE/src/Cache/Engine/FileEngine.php, line 141]
SplFileObject::fwrite() - [internal], line ??
Cake\Cache\Engine\FileEngine::set() - CORE/src/Cache/Engine/FileEngine.php, line 141
Cake\I18n\TranslatorRegistry::get() - CORE/src/I18n/TranslatorRegistry.php, line 206
Cake\I18n\I18n::getTranslator() - CORE/src/I18n/I18n.php, line 148
__ - CORE/src/I18n/functions.php, line 45
App\Controller\NewsController::view() - APP/Controller/NewsController.php, line 3420
Cake\Controller\Controller::invokeAction() - CORE/src/Controller/Controller.php, line 539
Cake\Controller\ControllerFactory::handle() - CORE/src/Controller/ControllerFactory.php, line 140
Cake\Controller\ControllerFactory::invoke() - CORE/src/Controller/ControllerFactory.php, line 115
Cake\Http\BaseApplication::handle() - CORE/src/Http/BaseApplication.php, line 317
Cake\Http\Runner::handle() - CORE/src/Http/Runner.php, line 77
Cake\Http\Middleware\CsrfProtectionMiddleware::process() - CORE/src/Http/Middleware/CsrfProtectionMiddleware.php, line 164
Cake\Http\Runner::handle() - CORE/src/Http/Runner.php, line 73
Cake\I18n\Middleware\LocaleSelectorMiddleware::process() - CORE/src/I18n/Middleware/LocaleSelectorMiddleware.php, line 61
Cake\Http\Runner::handle() - CORE/src/Http/Runner.php, line 73
Cake\Http\Middleware\BodyParserMiddleware::process() - CORE/src/Http/Middleware/BodyParserMiddleware.php, line 157
Cake\Http\Runner::handle() - CORE/src/Http/Runner.php, line 73
Notice: file_put_contents() [function.file-put-contents]: Write of 2561 bytes failed with errno=28 No space left on device in /www/wwwroot/www.adminso.com/vendor/cakephp/cakephp/src/Log/Engine/FileLog.php on line 140
Notice (8): SplFileObject::fwrite() [<a href='https://secure.php.net/splfileobject.fwrite'>splfileobject.fwrite</a>]: Write of 5131 bytes failed with errno=28 No space left on device [CORE/src/Cache/Engine/FileEngine.php, line 141]
SplFileObject::fwrite() - [internal], line ??
Cake\Cache\Engine\FileEngine::set() - CORE/src/Cache/Engine/FileEngine.php, line 141
Cake\Database\Schema\CachedCollection::describe() - CORE/src/Database/Schema/CachedCollection.php, line 85
Cake\ORM\Table::getSchema() - CORE/src/ORM/Table.php, line 513
Cake\ORM\Query::addDefaultTypes() - CORE/src/ORM/Query.php, line 290
Cake\ORM\Query::__construct() - CORE/src/ORM/Query.php, line 184
Cake\ORM\Table::query() - CORE/src/ORM/Table.php, line 1702
Cake\ORM\Table::find() - CORE/src/ORM/Table.php, line 1263
App\Controller\NewsController::action_() - APP/Controller/NewsController.php, line 6433
App\Controller\NewsController::get_data() - APP/Controller/NewsController.php, line 5701
App\Controller\NewsController::action_cache() - APP/Controller/NewsController.php, line 5625
App\Controller\NewsController::cache_action() - APP/Controller/NewsController.php, line 5281
App\Controller\NewsController::view() - APP/Controller/NewsController.php, line 3436
Cake\Controller\Controller::invokeAction() - CORE/src/Controller/Controller.php, line 539
Cake\Controller\ControllerFactory::handle() - CORE/src/Controller/ControllerFactory.php, line 140
Cake\Controller\ControllerFactory::invoke() - CORE/src/Controller/ControllerFactory.php, line 115
Cake\Http\BaseApplication::handle() - CORE/src/Http/BaseApplication.php, line 317
Notice: file_put_contents() [function.file-put-contents]: Write of 3153 bytes failed with errno=28 No space left on device in /www/wwwroot/www.adminso.com/vendor/cakephp/cakephp/src/Log/Engine/FileLog.php on line 140
Notice (8): SplFileObject::fwrite() [<a href='https://secure.php.net/splfileobject.fwrite'>splfileobject.fwrite</a>]: Write of 3642 bytes failed with errno=28 No space left on device [CORE/src/Cache/Engine/FileEngine.php, line 141]
SplFileObject::fwrite() - [internal], line ??
Cake\Cache\Engine\FileEngine::set() - CORE/src/Cache/Engine/FileEngine.php, line 141
Cake\Database\Schema\CachedCollection::describe() - CORE/src/Database/Schema/CachedCollection.php, line 85
Cake\ORM\Table::getSchema() - CORE/src/ORM/Table.php, line 513
Cake\ORM\Table::getPrimaryKey() - CORE/src/ORM/Table.php, line 653
Cake\ORM\Query::_addAssociationsToTypeMap() - CORE/src/ORM/Query.php, line 507
Cake\ORM\Query::contain() - CORE/src/ORM/Query.php, line 462
App\Controller\NewsController::action_() - APP/Controller/NewsController.php, line 6433
App\Controller\NewsController::get_data() - APP/Controller/NewsController.php, line 5701
App\Controller\NewsController::action_cache() - APP/Controller/NewsController.php, line 5625
App\Controller\NewsController::cache_action() - APP/Controller/NewsController.php, line 5281
App\Controller\NewsController::view() - APP/Controller/NewsController.php, line 3436
Cake\Controller\Controller::invokeAction() - CORE/src/Controller/Controller.php, line 539
Cake\Controller\ControllerFactory::handle() - CORE/src/Controller/ControllerFactory.php, line 140
Cake\Controller\ControllerFactory::invoke() - CORE/src/Controller/ControllerFactory.php, line 115
Cake\Http\BaseApplication::handle() - CORE/src/Http/BaseApplication.php, line 317
Cake\Http\Runner::handle() - CORE/src/Http/Runner.php, line 77
Notice: file_put_contents() [function.file-put-contents]: Write of 3107 bytes failed with errno=28 No space left on device in /www/wwwroot/www.adminso.com/vendor/cakephp/cakephp/src/Log/Engine/FileLog.php on line 140
Notice (8): SplFileObject::fwrite() [<a href='https://secure.php.net/splfileobject.fwrite'>splfileobject.fwrite</a>]: Write of 920 bytes failed with errno=28 No space left on device [CORE/src/Cache/Engine/FileEngine.php, line 141]
SplFileObject::fwrite() - [internal], line ??
Cake\Cache\Engine\FileEngine::set() - CORE/src/Cache/Engine/FileEngine.php, line 141
Cake\Database\Schema\CachedCollection::describe() - CORE/src/Database/Schema/CachedCollection.php, line 85
Cake\ORM\Table::getSchema() - CORE/src/ORM/Table.php, line 513
Cake\ORM\Query::addDefaultTypes() - CORE/src/ORM/Query.php, line 290
Cake\ORM\Query::__construct() - CORE/src/ORM/Query.php, line 184
Cake\ORM\Table::query() - CORE/src/ORM/Table.php, line 1702
Cake\ORM\Table::find() - CORE/src/ORM/Table.php, line 1263
App\Controller\NewsController::action_() - APP/Controller/NewsController.php, line 6539
App\Controller\NewsController::get_data() - APP/Controller/NewsController.php, line 5701
App\Controller\NewsController::action_cache() - APP/Controller/NewsController.php, line 5625
App\Controller\NewsController::cache_action() - APP/Controller/NewsController.php, line 5281
App\Controller\NewsController::view() - APP/Controller/NewsController.php, line 3436
Cake\Controller\Controller::invokeAction() - CORE/src/Controller/Controller.php, line 539
Cake\Controller\ControllerFactory::handle() - CORE/src/Controller/ControllerFactory.php, line 140
Cake\Controller\ControllerFactory::invoke() - CORE/src/Controller/ControllerFactory.php, line 115
Cake\Http\BaseApplication::handle() - CORE/src/Http/BaseApplication.php, line 317
Notice: file_put_contents() [function.file-put-contents]: Write of 3152 bytes failed with errno=28 No space left on device in /www/wwwroot/www.adminso.com/vendor/cakephp/cakephp/src/Log/Engine/FileLog.php on line 140
Notice (8): SplFileObject::fwrite() [<a href='https://secure.php.net/splfileobject.fwrite'>splfileobject.fwrite</a>]: Write of 184 bytes failed with errno=28 No space left on device [CORE/src/Cache/Engine/FileEngine.php, line 141]
SplFileObject::fwrite() - [internal], line ??
Cake\Cache\Engine\FileEngine::set() - CORE/src/Cache/Engine/FileEngine.php, line 141
Cake\Cache\Cache::write() - CORE/src/Cache/Cache.php, line 266
App\Controller\NewsController::action_() - APP/Controller/NewsController.php, line 6766
App\Controller\NewsController::get_data() - APP/Controller/NewsController.php, line 5701
App\Controller\NewsController::action_cache() - APP/Controller/NewsController.php, line 5625
App\Controller\NewsController::cache_action() - APP/Controller/NewsController.php, line 5281
App\Controller\NewsController::view() - APP/Controller/NewsController.php, line 3634
Cake\Controller\Controller::invokeAction() - CORE/src/Controller/Controller.php, line 539
Cake\Controller\ControllerFactory::handle() - CORE/src/Controller/ControllerFactory.php, line 140
Cake\Controller\ControllerFactory::invoke() - CORE/src/Controller/ControllerFactory.php, line 115
Cake\Http\BaseApplication::handle() - CORE/src/Http/BaseApplication.php, line 317
Cake\Http\Runner::handle() - CORE/src/Http/Runner.php, line 77
Cake\Http\Middleware\CsrfProtectionMiddleware::process() - CORE/src/Http/Middleware/CsrfProtectionMiddleware.php, line 164
Cake\Http\Runner::handle() - CORE/src/Http/Runner.php, line 73
Cake\I18n\Middleware\LocaleSelectorMiddleware::process() - CORE/src/I18n/Middleware/LocaleSelectorMiddleware.php, line 61
Cake\Http\Runner::handle() - CORE/src/Http/Runner.php, line 73
Notice: file_put_contents() [function.file-put-contents]: Write of 2792 bytes failed with errno=28 No space left on device in /www/wwwroot/www.adminso.com/vendor/cakephp/cakephp/src/Log/Engine/FileLog.php on line 140
Warning (512): long cache was unable to write 'd0060da5bedb735ba12e3439173371ed' to Cake\Cache\Engine\FileEngine cache [CORE/src/Cache/Cache.php, line 275]
Cake\Cache\Cache::write() - CORE/src/Cache/Cache.php, line 275
App\Controller\NewsController::action_() - APP/Controller/NewsController.php, line 6766
App\Controller\NewsController::get_data() - APP/Controller/NewsController.php, line 5701
App\Controller\NewsController::action_cache() - APP/Controller/NewsController.php, line 5625
App\Controller\NewsController::cache_action() - APP/Controller/NewsController.php, line 5281
App\Controller\NewsController::view() - APP/Controller/NewsController.php, line 3634
Cake\Controller\Controller::invokeAction() - CORE/src/Controller/Controller.php, line 539
Cake\Controller\ControllerFactory::handle() - CORE/src/Controller/ControllerFactory.php, line 140
Cake\Controller\ControllerFactory::invoke() - CORE/src/Controller/ControllerFactory.php, line 115
Cake\Http\BaseApplication::handle() - CORE/src/Http/BaseApplication.php, line 317
Cake\Http\Runner::handle() - CORE/src/Http/Runner.php, line 77
Cake\Http\Middleware\CsrfProtectionMiddleware::process() - CORE/src/Http/Middleware/CsrfProtectionMiddleware.php, line 164
Cake\Http\Runner::handle() - CORE/src/Http/Runner.php, line 73
Cake\I18n\Middleware\LocaleSelectorMiddleware::process() - CORE/src/I18n/Middleware/LocaleSelectorMiddleware.php, line 61
Cake\Http\Runner::handle() - CORE/src/Http/Runner.php, line 73
Cake\Http\Middleware\BodyParserMiddleware::process() - CORE/src/Http/Middleware/BodyParserMiddleware.php, line 157
Notice: file_put_contents() [function.file-put-contents]: Write of 2587 bytes failed with errno=28 No space left on device in /www/wwwroot/www.adminso.com/vendor/cakephp/cakephp/src/Log/Engine/FileLog.php on line 140
Notice (8): SplFileObject::fwrite() [<a href='https://secure.php.net/splfileobject.fwrite'>splfileobject.fwrite</a>]: Write of 137 bytes failed with errno=28 No space left on device [CORE/src/Cache/Engine/FileEngine.php, line 141]
SplFileObject::fwrite() - [internal], line ??
Cake\Cache\Engine\FileEngine::set() - CORE/src/Cache/Engine/FileEngine.php, line 141
Cake\Cache\Cache::write() - CORE/src/Cache/Cache.php, line 266
App\Controller\NewsController::action_() - APP/Controller/NewsController.php, line 6766
App\Controller\NewsController::get_data() - APP/Controller/NewsController.php, line 5701
App\Controller\NewsController::action_cache() - APP/Controller/NewsController.php, line 5625
App\Controller\NewsController::cache_action() - APP/Controller/NewsController.php, line 5281
App\Controller\NewsController::view() - APP/Controller/NewsController.php, line 3663
Cake\Controller\Controller::invokeAction() - CORE/src/Controller/Controller.php, line 539
Cake\Controller\ControllerFactory::handle() - CORE/src/Controller/ControllerFactory.php, line 140
Cake\Controller\ControllerFactory::invoke() - CORE/src/Controller/ControllerFactory.php, line 115
Cake\Http\BaseApplication::handle() - CORE/src/Http/BaseApplication.php, line 317
Cake\Http\Runner::handle() - CORE/src/Http/Runner.php, line 77
Cake\Http\Middleware\CsrfProtectionMiddleware::process() - CORE/src/Http/Middleware/CsrfProtectionMiddleware.php, line 164
Cake\Http\Runner::handle() - CORE/src/Http/Runner.php, line 73
Cake\I18n\Middleware\LocaleSelectorMiddleware::process() - CORE/src/I18n/Middleware/LocaleSelectorMiddleware.php, line 61
Cake\Http\Runner::handle() - CORE/src/Http/Runner.php, line 73
Notice: file_put_contents() [function.file-put-contents]: Write of 2792 bytes failed with errno=28 No space left on device in /www/wwwroot/www.adminso.com/vendor/cakephp/cakephp/src/Log/Engine/FileLog.php on line 140
Warning (512): long cache was unable to write 'dce8b5aaee3b4e67e6de80f4079bb99c' to Cake\Cache\Engine\FileEngine cache [CORE/src/Cache/Cache.php, line 275]
Cake\Cache\Cache::write() - CORE/src/Cache/Cache.php, line 275
App\Controller\NewsController::action_() - APP/Controller/NewsController.php, line 6766
App\Controller\NewsController::get_data() - APP/Controller/NewsController.php, line 5701
App\Controller\NewsController::action_cache() - APP/Controller/NewsController.php, line 5625
App\Controller\NewsController::cache_action() - APP/Controller/NewsController.php, line 5281
App\Controller\NewsController::view() - APP/Controller/NewsController.php, line 3663
Cake\Controller\Controller::invokeAction() - CORE/src/Controller/Controller.php, line 539
Cake\Controller\ControllerFactory::handle() - CORE/src/Controller/ControllerFactory.php, line 140
Cake\Controller\ControllerFactory::invoke() - CORE/src/Controller/ControllerFactory.php, line 115
Cake\Http\BaseApplication::handle() - CORE/src/Http/BaseApplication.php, line 317
Cake\Http\Runner::handle() - CORE/src/Http/Runner.php, line 77
Cake\Http\Middleware\CsrfProtectionMiddleware::process() - CORE/src/Http/Middleware/CsrfProtectionMiddleware.php, line 164
Cake\Http\Runner::handle() - CORE/src/Http/Runner.php, line 73
Cake\I18n\Middleware\LocaleSelectorMiddleware::process() - CORE/src/I18n/Middleware/LocaleSelectorMiddleware.php, line 61
Cake\Http\Runner::handle() - CORE/src/Http/Runner.php, line 73
Cake\Http\Middleware\BodyParserMiddleware::process() - CORE/src/Http/Middleware/BodyParserMiddleware.php, line 157
Notice: file_put_contents() [function.file-put-contents]: Write of 2587 bytes failed with errno=28 No space left on device in /www/wwwroot/www.adminso.com/vendor/cakephp/cakephp/src/Log/Engine/FileLog.php on line 140
Notice (8): unserialize() [<a href='https://secure.php.net/function.unserialize'>function.unserialize</a>]: Error at offset 24562 of 24565 bytes [APP/Controller/NewsController.php, line 5571]
unserialize - [internal], line ??
App\Controller\NewsController::action_cache() - APP/Controller/NewsController.php, line 5571
App\Controller\NewsController::cache_action() - APP/Controller/NewsController.php, line 5281
App\Controller\NewsController::view() - APP/Controller/NewsController.php, line 3698
Cake\Controller\Controller::invokeAction() - CORE/src/Controller/Controller.php, line 539
Cake\Controller\ControllerFactory::handle() - CORE/src/Controller/ControllerFactory.php, line 140
Cake\Controller\ControllerFactory::invoke() - CORE/src/Controller/ControllerFactory.php, line 115
Cake\Http\BaseApplication::handle() - CORE/src/Http/BaseApplication.php, line 317
Cake\Http\Runner::handle() - CORE/src/Http/Runner.php, line 77
Cake\Http\Middleware\CsrfProtectionMiddleware::process() - CORE/src/Http/Middleware/CsrfProtectionMiddleware.php, line 164
Cake\Http\Runner::handle() - CORE/src/Http/Runner.php, line 73
Cake\I18n\Middleware\LocaleSelectorMiddleware::process() - CORE/src/I18n/Middleware/LocaleSelectorMiddleware.php, line 61
Cake\Http\Runner::handle() - CORE/src/Http/Runner.php, line 73
Cake\Http\Middleware\BodyParserMiddleware::process() - CORE/src/Http/Middleware/BodyParserMiddleware.php, line 157
Cake\Http\Runner::handle() - CORE/src/Http/Runner.php, line 73
Cake\Routing\Middleware\RoutingMiddleware::process() - CORE/src/Routing/Middleware/RoutingMiddleware.php, line 161
Cake\Http\Runner::handle() - CORE/src/Http/Runner.php, line 73
Notice: file_put_contents() [function.file-put-contents]: Write of 2398 bytes failed with errno=28 No space left on device in /www/wwwroot/www.adminso.com/vendor/cakephp/cakephp/src/Log/Engine/FileLog.php on line 140
Notice (8): unserialize() [<a href='https://secure.php.net/function.unserialize'>function.unserialize</a>]: Error at offset 4041 of 4085 bytes [APP/Controller/NewsController.php, line 5571]
unserialize - [internal], line ??
App\Controller\NewsController::action_cache() - APP/Controller/NewsController.php, line 5571
App\Controller\NewsController::cache_action() - APP/Controller/NewsController.php, line 5281
App\Controller\NewsController::article_show() - APP/Controller/NewsController.php, line 4290
App\Controller\NewsController::view() - APP/Controller/NewsController.php, line 3822
Cake\Controller\Controller::invokeAction() - CORE/src/Controller/Controller.php, line 539
Cake\Controller\ControllerFactory::handle() - CORE/src/Controller/ControllerFactory.php, line 140
Cake\Controller\ControllerFactory::invoke() - CORE/src/Controller/ControllerFactory.php, line 115
Cake\Http\BaseApplication::handle() - CORE/src/Http/BaseApplication.php, line 317
Cake\Http\Runner::handle() - CORE/src/Http/Runner.php, line 77
Cake\Http\Middleware\CsrfProtectionMiddleware::process() - CORE/src/Http/Middleware/CsrfProtectionMiddleware.php, line 164
Cake\Http\Runner::handle() - CORE/src/Http/Runner.php, line 73
Cake\I18n\Middleware\LocaleSelectorMiddleware::process() - CORE/src/I18n/Middleware/LocaleSelectorMiddleware.php, line 61
Cake\Http\Runner::handle() - CORE/src/Http/Runner.php, line 73
Cake\Http\Middleware\BodyParserMiddleware::process() - CORE/src/Http/Middleware/BodyParserMiddleware.php, line 157
Cake\Http\Runner::handle() - CORE/src/Http/Runner.php, line 73
Cake\Routing\Middleware\RoutingMiddleware::process() - CORE/src/Routing/Middleware/RoutingMiddleware.php, line 161
Notice: file_put_contents() [function.file-put-contents]: Write of 2489 bytes failed with errno=28 No space left on device in /www/wwwroot/www.adminso.com/vendor/cakephp/cakephp/src/Log/Engine/FileLog.php on line 140
Notice (8): unserialize() [<a href='https://secure.php.net/function.unserialize'>function.unserialize</a>]: Error at offset 12273 of 12277 bytes [APP/Controller/NewsController.php, line 5571]
unserialize - [internal], line ??
App\Controller\NewsController::action_cache() - APP/Controller/NewsController.php, line 5571
App\Controller\NewsController::cache_action() - APP/Controller/NewsController.php, line 5281
App\Controller\NewsController::article_show() - APP/Controller/NewsController.php, line 4310
App\Controller\NewsController::view() - APP/Controller/NewsController.php, line 3822
Cake\Controller\Controller::invokeAction() - CORE/src/Controller/Controller.php, line 539
Cake\Controller\ControllerFactory::handle() - CORE/src/Controller/ControllerFactory.php, line 140
Cake\Controller\ControllerFactory::invoke() - CORE/src/Controller/ControllerFactory.php, line 115
Cake\Http\BaseApplication::handle() - CORE/src/Http/BaseApplication.php, line 317
Cake\Http\Runner::handle() - CORE/src/Http/Runner.php, line 77
Cake\Http\Middleware\CsrfProtectionMiddleware::process() - CORE/src/Http/Middleware/CsrfProtectionMiddleware.php, line 164
Cake\Http\Runner::handle() - CORE/src/Http/Runner.php, line 73
Cake\I18n\Middleware\LocaleSelectorMiddleware::process() - CORE/src/I18n/Middleware/LocaleSelectorMiddleware.php, line 61
Cake\Http\Runner::handle() - CORE/src/Http/Runner.php, line 73
Cake\Http\Middleware\BodyParserMiddleware::process() - CORE/src/Http/Middleware/BodyParserMiddleware.php, line 157
Cake\Http\Runner::handle() - CORE/src/Http/Runner.php, line 73
Cake\Routing\Middleware\RoutingMiddleware::process() - CORE/src/Routing/Middleware/RoutingMiddleware.php, line 161
Notice: file_put_contents() [function.file-put-contents]: Write of 2491 bytes failed with errno=28 No space left on device in /www/wwwroot/www.adminso.com/vendor/cakephp/cakephp/src/Log/Engine/FileLog.php on line 140 A screenshot of a Microsoft paper reveals that GPT-3.5 only has 20 billion parameters? The AI world is shaking, and netizens exclaim that it's too outrageous! - AdminSo
A screenshot of a Microsoft paper reveals that GPT-3.5 only has 20 billion parameters? The AI world is shaking, and netizens exclaim that it's too outrageous!
Xinzhiyuan ReportEditor: Editorial DepartmentIntroduction to New Intelligence ElementA recent paper by Microsoft revealed that the parameter quantity of GPT-3.5 is only 20B, far less than the 175B previously announced by GPT-3
Xinzhiyuan Report
Editor: Editorial Department
Introduction to New Intelligence ElementA recent paper by Microsoft revealed that the parameter quantity of GPT-3.5 is only 20B, far less than the 175B previously announced by GPT-3. Netizens say that ChatGPT's ability seems to be 'worthy' of this size?
Today, the big model circle was flooded with screenshots from Microsoft's paper. What's going on?
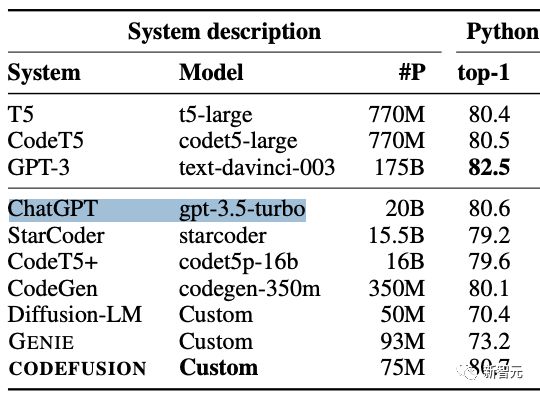
Just a few days ago, Microsoft published a paper and posted it on arXiv, which proposed a small-scale diffusion model with only 75M parameters - CodeFusion.
In terms of performance, the CodeFusion with 75 million parameters can rival the state-of-the-art 350M-175B model in terms of top-1 accuracy.
Paper address: https://arxiv.org/abs/2310.17680
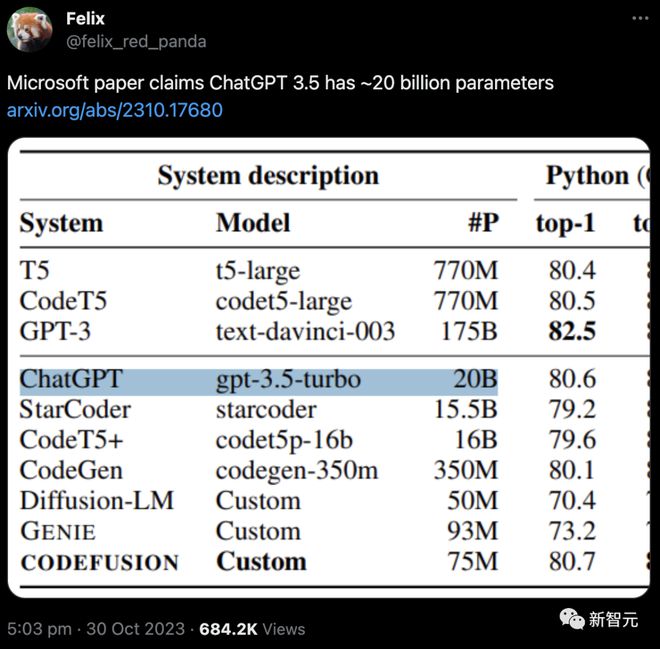
When the author compared ChatGPT (gpt-3.5 turbo), the nominal parameter quantity was only 20B!
Prior to this, everyone's speculation about the number of GPT-3.5 parameters was 175 billion, which is equivalent to a reduction of almost ten times!
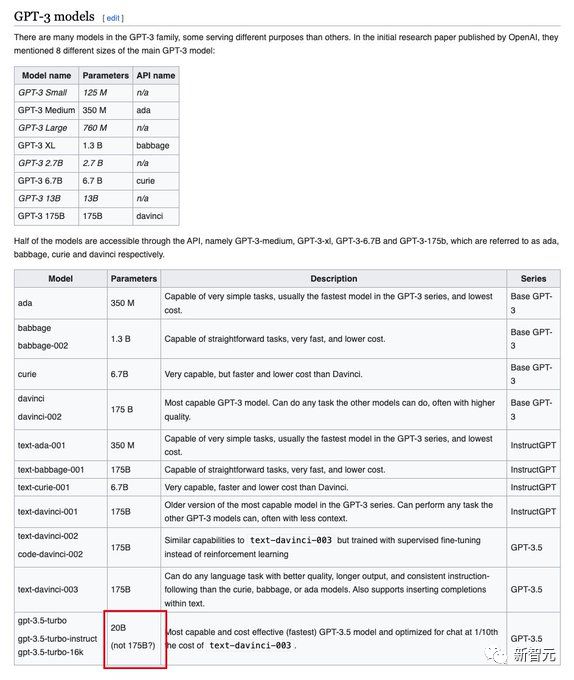
According to the disclosure of this paper, netizens also updated the introduction of GPT-3.5 on Wikipedia and directly changed the parameter size to 20B.
As soon as the news came out, it went straight to Zhihu Hot Search, causing netizens to explode.
Someone suggested that I quickly turn around and review my previous blog post on model distillation.
Is it an 'oolong' or a 'fact'?
As soon as netizens posted their explosive posts, they immediately sparked a heated discussion.
At present, more than 680000 people have come to watch.
The old man said that several authors of the paper are also using Twitter, and it is estimated that they will come down to explain in person soon.
And for this mysterious "20B", netizens also have diverse opinions.
Some people speculate that this is likely due to the author's mistake in typing. For example, it was originally 120B or 200B.
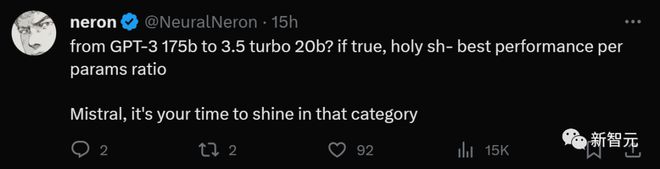
Based on various evaluations in reality, there are indeed many small models that can achieve results similar to ChatGPT, such as Mistral 7B.
Perhaps this also indirectly confirms that the GPT-3.5 volume is really not large.
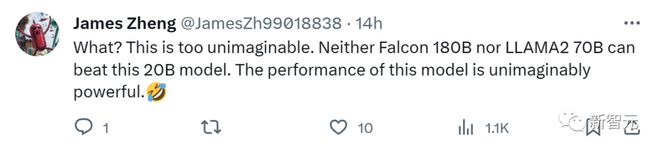
Many netizens also believe that the parameters of 20B may be accurate and exclaim:
This is too unimaginable! Both Falcon-180B and Llama2-70B cannot defeat this 20B model
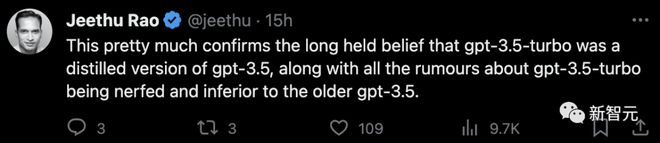
Some netizens also believe that gpt-3.5 turbo is a refined version of gpt-3.5.
The "leakage" of this parameter confirms rumors that the performance of GPT-3.5 turbo is not as good as the old version of GPT-3.5 from the side.
However, according to the official documentation of OpenAI, except for the text avinci and code davinci that are no longer in use, all members of the GPT-3.5 family are based on gpt-3.5 turbo.
Microsoft Releases CodeFusion
The Microsoft paper that exposed GPT3.5 with only 20B parameters aims to introduce a diffusion model for code generation.
Researchers evaluated this model, CodeFusion, based on the task of generating natural language code for Bash, Python, and Microsoft Excel Conditional Format (CF) rules.
Experiments have shown that CodeFusion (with only 75M parameters) is comparable in top-1 accuracy to state-of-the-art LLM (350M-175B parameters), and has excellent performance and parameter ratio in top-3 and top-5 accuracy.
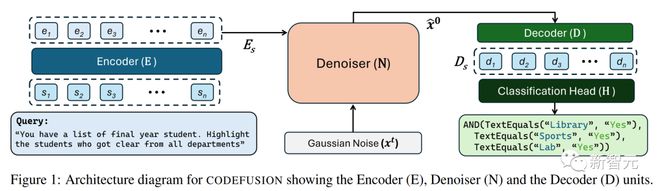
Model Architecture
CODEFUSION is used for code generation tasks, and its training is divided into two stages. The first stage is unsupervised pre training, and the second stage is supervised fine-tuning.
In the first stage, CODEFUSION uses unlabeled code fragments to train the noise canceller and decoder. It also uses a trainable embedding layer L to embed code fragments into continuous space.
In the second stage, CODEFUSION undergoes supervised fine-tuning, using text code to match the data. At this stage, the encoder, noise canceller, and decoder will all be adjusted to better perform the task.
In addition, CODEFUSION also draws on previous research on text diffusion and incorporates the hidden representation D from the decoder into the model. This is to improve the performance of the model. During the training process, at different steps, the model introduces some noise and calculates the loss function to ensure that the generated code fragments better meet the expected standards.
In summary, CODEFUSION is a small model that performs code generation work, continuously improving its performance through two stages of training and noise introduction. The inspiration for this model comes from research on text diffusion and improves the loss function by incorporating hidden representations of decoders to better generate high-quality code fragments.
Evaluation results
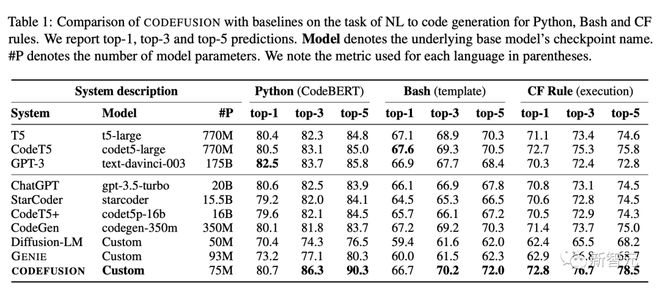
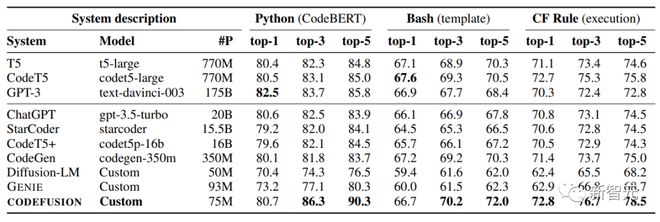
The following table summarizes the performance of the CODEFUSION model and various baseline models under the top-1, top-3, and top-5 settings.
In top-1, the performance of CODEFUSION is comparable to that of autoregressive models, and even performs better in some cases, especially in Python tasks where only GPT-3 (175B) performs slightly better than CODEFUSION (75M). However, in terms of top-3 and top-5, CODEFUSION is significantly superior to all baseline models.
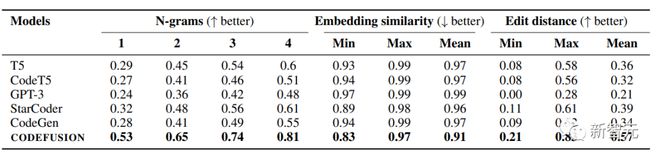
The table below shows the average diversity results of CODEFUSION and autoregressive models (including T5, CodeT5, StarCoder, CodeGen, GPT-3) on various benchmark tasks, examining the results generated by the first five generations of each model.
Compared to autoregressive models, CODEFUSION generates more diverse results and performs better.
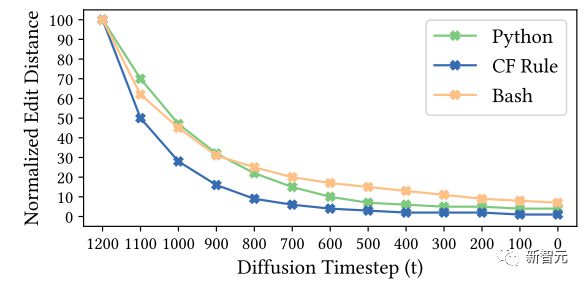
This method helps to summarize and demonstrate the gradual progress of the CODEFUSION model, as shown in the following figure.
Having said so much, what is the parameter count for GPT-3.5? What is the technical and other connection between GPT-4 and GPT-3.5?
Is GPT-3.5 an integration of small expert models or a generalist model? Is it through distillation of larger models or training with larger data?
The answers to these questions can only be revealed when they are truly open source.
Disclaimer: The content of this article is sourced from the internet. The copyright of the text, images, and other materials belongs to the original author. The platform reprints the materials for the purpose of conveying more information. The content of the article is for reference and learning only, and should not be used for commercial purposes. If it infringes on your legitimate rights and interests, please contact us promptly and we will handle it as soon as possible! We respect copyright and are committed to protecting it. Thank you for sharing.