Big models cannot replace code farmers! Princeton University of Chicago Surprisingly Discovered: GPT-4 has a success rate of 0 in solving GitHub programming problems
Xinzhiyuan ReportEditor: Editorial DepartmentIntroduction to New Intelligence ElementAI coding tools like ChatGPT are coming unstoppably, and StackOverflow has laid off employees again! However, Princeton and Zhida unexpectedly found that when faced with the real world GitHub problem, the GPT-4 solution rate was actually 0%.StackOverflow, has been created and flown by ChatGPT!Due to a large influx of code farmers to ChatGPT and GithubCopilot, StackOverflow today had to announce layoffs of over 100 people, almost one-third of the workforce

Xinzhiyuan Report
Editor: Editorial Department
Introduction to New Intelligence ElementAI coding tools like ChatGPT are coming unstoppably, and StackOverflow has laid off employees again! However, Princeton and Zhida unexpectedly found that when faced with the real world GitHub problem, the GPT-4 solution rate was actually 0%.
StackOverflow, has been created and flown by ChatGPT!
Due to a large influx of code farmers to ChatGPT and GithubCopilot, StackOverflow today had to announce layoffs of over 100 people, almost one-third of the workforce.

So, are AI coding tools like ChatGPT really going to disrupt the entire industry?
However, a recent study by Princeton and Chicago University found that LLM may not be as easy to replace farmers.

Paper address: https://arxiv.org/abs/2310.06770
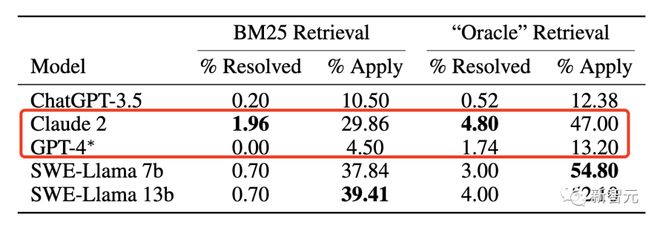
In front of 2294 real GitHub problems, the pass rate of GPT-4 in solving random GitHub problems is unexpectedly 0%!
Even the best model, Claude2, can only solve 1.96% of it.
Will farmers be unemployed due to ChatGPT? The answer is - definitely not at the moment.
Either adapt or perish
As the favorite code assistance website for every developer around the world, StackOverflow was in a good position before this, causing a recruitment frenzy last year, with the entire company's staff doubling to 540 people.
However, since OpenAI released ChatGPT in November last year, everything has changed.

The help provided by AI chat robots is more specific than the forum posts 5 years ago. Through LLM, developers can provide timely and accurate code cutting, optimization suggestions, and instructions on each line of code being executed.
Although the answers provided by LLM are not 100% reliable, the code has unique capabilities that can be immediately validated by testing in an IDE integrated development environment, making writing code an ideal use case for ChatGPT.
Therefore, the traffic of StackOverflow has greatly decreased, and AI programming tools such as ChatGPT and GithubCopilot driven by GPT-4 have become new destinations for code farmers.
Today, CEO RashanthChandrasekar announced that StackOverflow has laid off more than 100 employees, accounting for 28% of its total workforce.

The CEO's explanation for layoffs is that under macroeconomic pressure, StackOverflow is striving to embark on a profitable path and continuously launching product innovation.
Crossing a river and demolishing a bridge?
The biggest irony of ChatGPT's impact on StackOverflow lies in the fact that the powerful capabilities of large language models largely come from crawling websites like StackOverflow.
The big language model sucks up this data without giving back anything. What would happen if all data sources were forced out of this business?
Nowadays, many technology companies already face an urgent problem: if programmers decrease, artificial data will decrease.
How can a new AI model be trained without the latest data?
Want to use our data? Take the money
One is to develop their own AI coding tool OverflowAI, and the other is to directly seek cooperation with technology companies like OpenAI, as these companies will use StackOverflow data to build AI models.

It is reported that OpenAI is developing a web crawler control for ChatGPT, so that data from websites like StackOverflow will not be crawled.
The CEO stated that StackOverflow has made a clear position: whoever wants to use our data to train LLM will pay.
The CEO believes that websites like StackOverflow are crucial for the development of big language models, and in order to progress, they need to train on new knowledge.

PrashanthChandrasekar, CEO of StackOverflow
LLM wants to retrieve the code farm, it's still a long way off
So, can the big language model really take code farming?
The Princeton and Zhida teams have found that it's not that easy!

In the latest paper, researchers have proposed a novel framework, SWE-bench, to evaluate the ability of large models to solve 2294 real GitHub problems.
It was found that leading large models such as GPT-4 and Claude2 have a problem-solving ability of only 5%.
More specifically, GPT-4 can solve the random GitHub problem with a pass rate of 0%, while the optimal model Claude2 can only solve 1.96% of it.
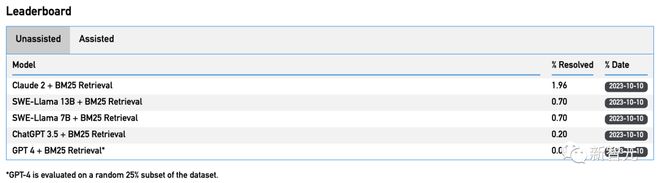
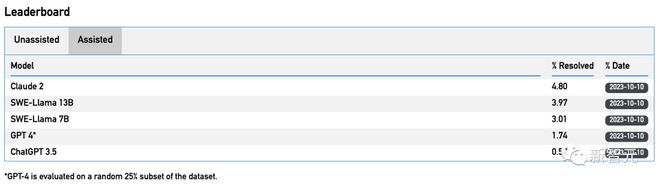
It is worth mentioning that when using BM-25 to retrieve the relevant code files for each issue, only 23% of the patches written by Claude2 were valid (which can be used for repo), and only~1% truly solved the problem.
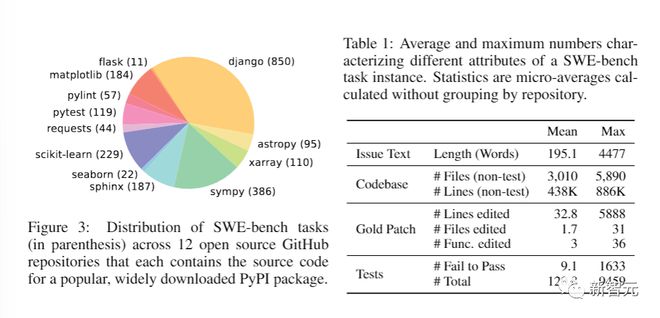
In addition, the performance of different models in solving 12 popular Python library problems also varies.
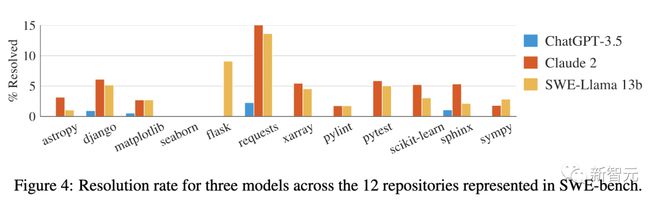
The GPT-4 model achieved such results, which is truly surprising, as many people have already regarded it as a "programming tool".
But it's important to see clearly the true strength of AI, and not get worried about being brushed and scored.
Some netizens expressed that this is the best answer to the question of whether code farmers are unemployed due to programming.

Finally, someone created a real Eval dataset for the code model, and HumEval is just a leetcode surface of LLM. We all know that this is a wrong metric for human engineers. Less than 4% sounds right, as large models are still far from fully autonomous.
So, is it true that SWE-bench evaluates the capabilities of large models?
SWE-bench: Designed specifically for encoding models
In this study, the author found that many benchmarks for evaluating the encoding ability of large models have reached saturation, making it impossible to measure the true strength of large models.
For example, in HumanEval, the challenge problem is too simple, and LLM only requires a few lines of code to solve independent problems.
However, in reality, software engineering is not so simple.

Fixing a bug may require browsing a vast resource library, understanding the relationships between functions in different files, or discovering a small error in complex code.
Inspired by this, researchers from Princeton and Chicago introduced SWE-bench.
SWE-bench obtains task instances from real Python code libraries by connecting GitHub issues and solving related testing merge request solutions.
As shown in the figure, the task of the model (usually error reports or feature requests) is to resolve issues submitted to the GitHub repository.
Each task requires generating a patch and describing the changes to be applied to the existing code base.
Then use the warehouse's testing framework SWE-bench to evaluate the modified code base.

In order to find high-quality large-scale task instances, researchers conducted three stages of screening:

Phase 1: Warehouse selection and data search.
Firstly, pull requests (PRs) were collected from 12 popular open source Python code libraries on GitHub, resulting in a total of approximately 90000 PRs.
Researchers will focus on popular warehouses as they tend to be better maintained, have clear guidelines for contributors, and have better testing coverage. Each PR has a related code base, which is the warehouse status before PR consolidation.
Phase 2: Attribute based filtering.
The method for creating candidate tasks is to select a merged PR that meets the following conditions: (1) solves the GitHub problem; (2) The test file for the warehouse has been modified, indicating that the user is likely contributing tests to check if the issue has been resolved.
Phase 3: Execution based filtering.
For each candidate task, the test content of PR will be applied, and the relevant test results before and after applying other content of PR will be recorded.
Researchers will filter out task instances that do not have at least one test, and the status of these tests will change from failed to passed (hereinafter referred to as "failed to passed"). In addition, instances that cause installation or running errors will also be filtered out.
Through the screening of these stages, the original 90000 PRs were filtered into 2294 task instances, which constitute the SWE-bench.
As shown in Figure 3, the final classification of these task instances in different resource libraries is shown, and the table is the main feature of SWE-bench task instances.
Researchers emphasize that these code libraries are large, containing thousands of files, and reference pull requests typically modify multiple files simultaneously.
Compared to existing LM programming benchmarks, SWE-bench has multiple advantages.
This includes utilizing real-world settings for user submitted issues and solutions, diverse inputs featuring unique code issues from 12 resource libraries, a powerful evaluation framework based on execution, and the ability to continuously update benchmarks with new instances with minimal human intervention.
LLM Task: Edit Code Library, Resolve Issues
Researchers will provide a textual description of the problem to the large model, as well as a complete code base.
The task of a large model is to edit the code base to solve problems.
In practice, researchers represent modifications as patch files, which specify which lines in the code base to modify to solve the problem.
How to evaluate the plan provided by LLM?
Researchers will use Unix patch programs to apply the generated patches to the code base, and then perform unit and system tests related to task instances.
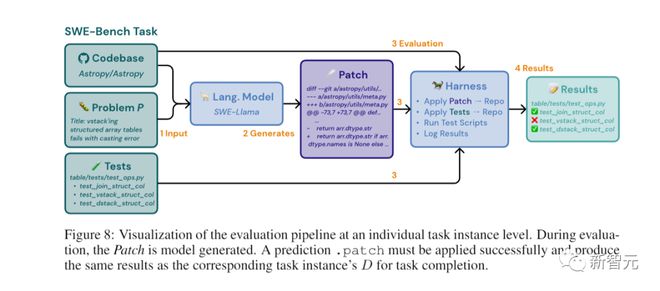
If the patch is successfully applied and all of these tests are passed, it can be considered that the LLM recommended solution has successfully solved the problem.
The benchmark metric is the percentage of resolved task instances.
Building a unique dataset for SWE-bench
Traditional NLP benchmarks typically only involve short input and output sequences, and consider some "human" issues specifically created for the benchmark.
In contrast, in order to construct SWE-bench, researchers injected unique attributes into the dataset.
For example, real software engineering tasks are used.
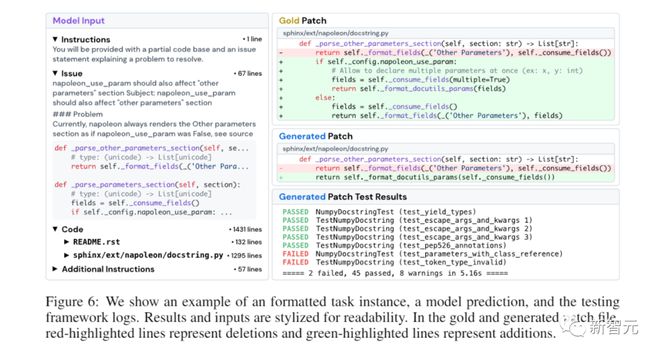
Due to the fact that each task instance in SWE-bench contains a large and complex code base and related problem descriptions, solving SWE-bench requires experienced software engineers with complex skills and knowledge, but in traditional code generation benchmarks, these are usually not evaluated.
Moreover, the collection process can be easily applied to any Python repository on GitHub with almost no human intervention.
Therefore, researchers can extend SWE-bench by continuously providing new task instances and evaluating language models for issues created after the training date, ensuring that no solutions are included in the training corpus.
In addition, the researchers also ensured different long inputs, robust evaluation, cross contextual code editing, and a wide range of solutions in the benchmark.
Fine tune SWE-Llama
Next, it's time to evaluate the effectiveness of open and proprietary models in the SWE-bench framework.
However, researchers have found that the existing CodeLlama fine-tuning model cannot follow detailed instructions to generate code edits across the entire resource library, and typically outputs placeholder responses or irrelevant code.
To evaluate the capabilities of these models, researchers conducted supervised fine-tuning (SFT) on the CodeLlama Python model with 7 billion parameters and the CodeLlama Python model with 13 billion parameters.
The resulting model is a specialized warehouse editor that can run on consumer grade hardware and solve GitHub problems.

Big models are all defeated
Next, the researchers evaluated the GPT-3.5, GPT-4, Cluade2, and fine-tuned models.
It was found that all models failed - they were unable to solve all problems except for the simplest ones.
For example, Claude2 and GPT-4 can only solve 4.8% and 1.7% of tasks, respectively.
After using the BM25 retriever, the performance of Claude2 further decreased to 1.96%.
The difficulty of different resource libraries varies.
If performance is segmented by resource pool, it will be found that all models exhibit similar trends in different resource pools.
Nevertheless, the problems addressed by each model do not necessarily overlap widely. For example, in Oracle settings, the performance of Claude2 and SWE-Llama13b is equivalent, with each model solving 110 and 91 instances, respectively.
The difficulty is related to the length of the context.
The model can be pre trained on long code sequences, but typically requires generating a single function at once and providing limited context to determine the framework of the problem.
As shown in the figure, it can be seen that as the total length of the context increases, the performance of Claude2 significantly decreases, which can also be observed in other models.
Even if increasing the maximum context size of BM25 increases the recall rate relative to Oracle files, performance will still decrease because the model cannot locate problematic code in the vast vocabulary.
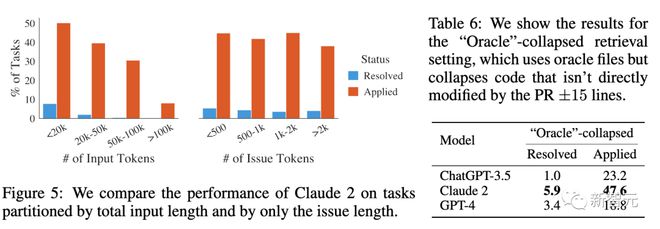
The difficulty is not related to the problem resolution date.
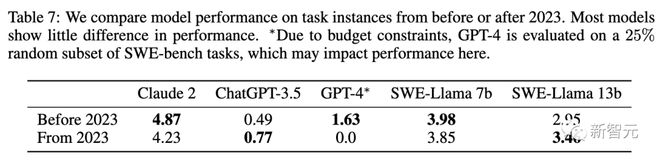
In Table 7, the model results by date are displayed for PRs created before or after 2023 under the "Oracle" search setting.
For most models, except for GPT-4, the performance difference before or after this date is not significant.
In addition, research has found that fine-tuning models are sensitive to changes in context distribution, and generating patches is easier than generating the entire file. Moreover, large models tend to generate shorter and simpler edits.
LLM cannot replace programmers, but it can accelerate workflows
Some netizens have aspirations and hopes for the future of the "generalist model".
That's right, this is also my experience. The generalist model is not good enough and does not have a wide enough context length, making it impossible to encode on its own except for relatively short code fragments.
But I think it's just a matter of time. I can foresee that in the near future, LLM, a generalist who has received specific training, will become a very professional model.
Although large models cannot replace programmers, they can accelerate their workflows. In the past, a team of 10 people was needed, but now it may only require 4 people. This will free up resources for other goals prepared by the company.
Rather than laying off employees to save money, it's better to have developers complete great careers with astonishing speed!

References:
https://www.reddit.com/r/MachineLearning/comments/1795iiz/can_ai_replace_developers_princeton_and/
https://twitter.com/_carlosejimenez/status/1711714120175681552
https://www.swebench.com/
https://futurism.com/the-byte/stack-overflow-layoffs-ai
https://arstechnica.com/gadgets/2023/10/after-chatgpt-disruption-stack-overflow-lays-off-28-percent-of-staff/?comments=1&comments -Page=1
Tag: of Big models cannot replace code farmers Princeton University
Disclaimer: The content of this article is sourced from the internet. The copyright of the text, images, and other materials belongs to the original author. The platform reprints the materials for the purpose of conveying more information. The content of the article is for reference and learning only, and should not be used for commercial purposes. If it infringes on your legitimate rights and interests, please contact us promptly and we will handle it as soon as possible! We respect copyright and are committed to protecting it. Thank you for sharing.

