Improve accuracy by 7.8%! The first multimodal open world detection large model MQ-Det on NeuroIPS2023
Xinzhiyuan ReportEditor: LRSIntroduction to New Intelligence ElementOn the basis of existing text query based detection models, MQ-Det incorporates visual example query functionality while retaining high generalization performance and fine-grained multimodal queries, achieving SOTA performance on the ODinW-35 benchmark.The current open world object detection models mostly follow the pattern of text queries, which use category text descriptions to query potential targets in the target image

Xinzhiyuan Report
Editor: LRS
Introduction to New Intelligence ElementOn the basis of existing text query based detection models, MQ-Det incorporates visual example query functionality while retaining high generalization performance and fine-grained multimodal queries, achieving SOTA performance on the ODinW-35 benchmark.
The current open world object detection models mostly follow the pattern of text queries, which use category text descriptions to query potential targets in the target image. However, this approach often faces the problem of being "broad but not precise".

Paper link: https://arxiv.org/abs/2305.18980
Code address: https://github.com/YifanXu74/MQ-Det
To this end, researchers from institutions such as Automation of the Chinese Academy of Sciences have proposed an object detection MQ-Det based on multimodal queries, as well as the first open world detection model that supports both text description and visual example queries.
On the basis of existing text query based detection models, MQ-Det has added visual example query functionality. By introducing a plug and play gated perception structure and a visual conditioned mask language prediction training mechanism, the detector maintains high generalization while supporting fine-grained multimodal queries, providing users with more flexible choices to adapt to different scenarios.
Its simple and effective design is compatible with existing mainstream detection models and has a wide range of applications.
Experiments have shown that multimodal queries can significantly enhance the open world object detection capabilities of mainstream detection large models. For example, on the benchmark detection dataset LVIS, there is no need for downstream task model fine-tuning to improve the GLIP accuracy of mainstream detection large models by about 7.8% AP, and an average improvement of 6.3% AP on 13 benchmark small sample downstream tasks.
From Text Query to Multimodal Query
A picture is worth a thousand words
With the rise of image and text pre training, object detection has gradually entered the stage of open world perception through the open semantics of text.
For this reason, many detection models follow the pattern of text queries, which use category text descriptions to query potential targets in the target image.
However, this approach often faces the problem of being 'broad but not precise'.
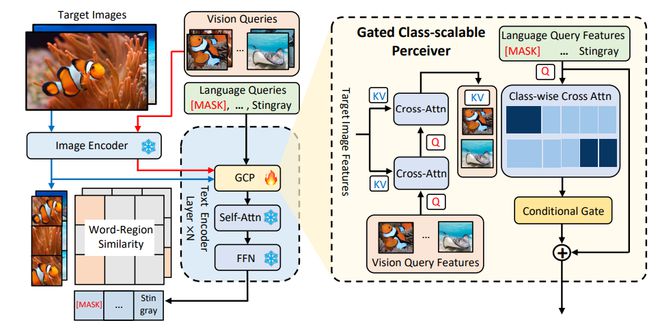
Figure 1 MQ-Det method architecture diagram
For example, the detection of fine-grained objects (fish species) in Figure 1 often makes it difficult to describe various fine-grained fish species with limited text; Category ambiguity, bat can refer to both bats and rackets.
However, the above problems can be solved through image examples. Compared to text, images can provide richer feature clues for the target object, but at the same time, text has strong generalization ability.
Therefore, how to organically combine the two query methods has become a natural idea.
The difficulty of obtaining multimodal query capability: There are three challenges in obtaining a model with multimodal queries:
1. Directly fine-tuning with limited image examples can easily lead to catastrophic forgetting;
2. Training a large detection model from scratch will have good generalization but huge cost. For example, single card training of GLIP [1] requires training with 30 million data for 480 days.
Multimodal query object detection: Based on the above considerations, the author proposes a simple and effective model design and training strategy - MQ-Det
MQ-Det inserts a small number of Gated Perception Modules (GCPs) into the existing frozen text query detection large model to receive input from visual examples, and designs a visual condition mask language prediction training strategy to efficiently obtain high-performance multimodal query detectors.
MQ Net: A Plug and Play Multimodal Query Model Architecture
Door control perception module
1Door control perception moduleGCPGCP
For the i-th category, enter visual example v_ i. It first performs cross attention (X-MHA) with the target image to enhance its representation ability, and then each category of text t_ I will cross focus with visual examples of the corresponding category to obtain, and then use a gate control module to convert the original text t_ Fusion of text with visual augmentation to obtain the output of the current layer
This simple design follows three principles: (1) category scalability; (2) Semantic completeness; (3) Anti forgetting ability, specific discussion can be found in the original text.
MQ-Det Efficient Training Strategy
Modulation training based on frozen language query detector
Due to the fact that the current pre trained detection models for text queries already have good generalization, the author believes that only minor adjustments with visual details are needed based on the original text features.
In the article, there is also specific experimental evidence that fine-tuning the parameters of the original pre trained model after opening it can easily lead to catastrophic forgetting, and instead lose the ability to detect the open world.
Therefore, on the basis of pre trained detectors for frozen text queries, MQ-Det can efficiently insert visual information into existing text query detectors by modulating only the GCP module for training insertion.
In the article, the author applies the structural design and training techniques of MQ-Det to the current SOTA models GLIP [1] and GroundingDINO [2] to verify the universality of the method.
A masked language prediction training strategy based on visual conditions
The author also proposes a visually conditioned masked language prediction training strategy to address the problem of learning inertia caused by frozen pre training models.
The so-called learning inertia refers to the tendency of the detector to maintain the features of the original text query during the training process, thereby ignoring the newly added visual query features.
For this reason, MQ-Det randomly replaces text tokens with [MASK] tokens during training, forcing the model to learn from the visual query feature side, namely:
Although this strategy is simple, it is very effective, and from the experimental results, it has brought significant performance improvements.
experimental result
Finetring free
Compared to traditional zero shot evaluations that only use category text for testing, MQ-Det proposes a more practical evaluation strategy: finetuning free
It is defined as: without any downstream fine-tuning, users can use category text, image examples, or a combination of both to perform object detection.
Under the setting of finetuning free, MQ-Det selected 5 visual examples for each category and combined them with category text for object detection. However, other existing models do not support visual queries and can only use pure text descriptions for object detection.
The following table shows the detection results on LVISMiniVal and LVISv1.0. It can be observed that the introduction of multimodal queries has significantly improved the ability to detect open world objects.
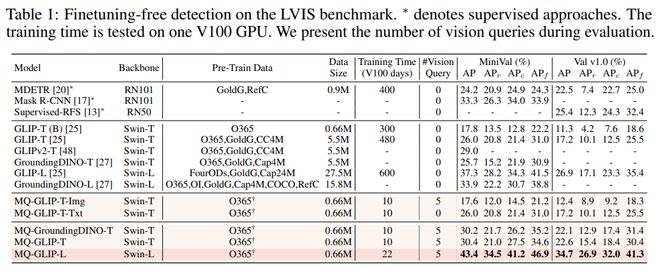
Table 1: Fine tuning free performance of various detection models in the LVIS benchmark dataset
From Table 1, it can be seen that MQ-GLIP-L has increased AP by more than 7% on the basis of GLIP-L, and the effect is very significant!
Few shot evaluation
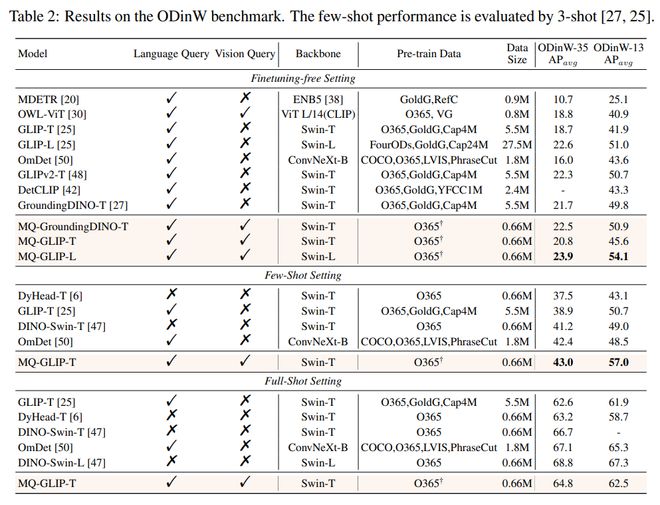
Table 2 Performance of each model in 35 detection tasks ODinW-35 and its 13 subsets ODinW-13
The author further conducted comprehensive experiments on 35 downstream detection tasks ODinW-35. From Table 2, it can be seen that in addition to its powerful finetuning free performance, MQ-Det also has good small sample detection capabilities, further confirming the potential of multimodal queries. Figure 2 also shows the significant improvement of MQ-Det on GLIP.
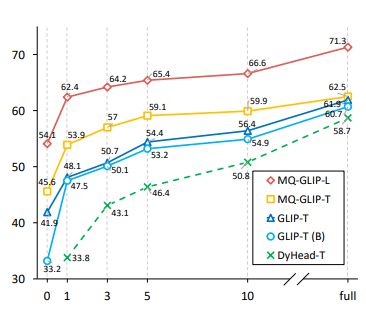
Figure 2 Comparison of data utilization efficiency; Horizontal axis: number of training samples, vertical axis: average AP on OdinW-13
Prospects for Multimodal Query Object Detection
As a research field based on practical applications, object detection places great emphasis on the implementation of algorithms.
Although previous pure text query object detection models have shown good generalization, it is difficult for text to cover fine-grained information in actual open world detection, and the rich information granularity in images perfectly fills this loop.
At this point, we can find that text is broad but not precise, and images are fine but not broad. If we can effectively combine the two, namely multimodal queries, it will further advance open world object detection.
MQ-Det has taken the first step in multimodal queries, and its significant performance improvement also demonstrates the enormous potential of object detection in multimodal queries.
At the same time, the introduction of text descriptions and visual examples provides users with more choices, making object detection more flexible and user-friendly.
References:
1. GroundedLanguage ImagePre train ninghttps://arxiv.org/abs/2112.038
2. GroundingDINO: MarryingDINO with GroundedPre Training for Open SetObject Detect tionhttps://arxiv.org/abs/2303.05499
Tag: Improve accuracy by 7.8% The first multimodal open world
Disclaimer: The content of this article is sourced from the internet. The copyright of the text, images, and other materials belongs to the original author. The platform reprints the materials for the purpose of conveying more information. The content of the article is for reference and learning only, and should not be used for commercial purposes. If it infringes on your legitimate rights and interests, please contact us promptly and we will handle it as soon as possible! We respect copyright and are committed to protecting it. Thank you for sharing.

