if (!$mask) { file_put_contents($pathname, $message . "\n", FILE_APPEND);
file_put_contents - [internal], line ??
Cake\Log\Engine\FileLog::log() - CORE/src/Log/Engine/FileLog.php, line 140
Cake\Log\Log::write() - CORE/src/Log/Log.php, line 392
Cake\Log\Log::warning() - CORE/src/Log/Log.php, line 477
DebugKit\ToolbarService::isSuspiciouslyProduction() - ROOT/vendor/cakephp/debug_kit/src/ToolbarService.php, line 169
DebugKit\ToolbarService::isEnabled() - ROOT/vendor/cakephp/debug_kit/src/ToolbarService.php, line 105
DebugKit\Plugin::bootstrap() - ROOT/vendor/cakephp/debug_kit/src/Plugin.php, line 48
Cake\Http\BaseApplication::pluginBootstrap() - CORE/src/Http/BaseApplication.php, line 182
Cake\Http\Server::bootstrap() - CORE/src/Http/Server.php, line 111
Cake\Http\Server::run() - CORE/src/Http/Server.php, line 79
[main] - ROOT/webroot/index.php, line 40
Notice: file_put_contents() [function.file-put-contents]: Write of 1108 bytes failed with errno=28 No space left on device in /www/wwwroot/www.adminso.com/vendor/cakephp/cakephp/src/Log/Engine/FileLog.php on line 140
Notice (8): SplFileObject::fwrite() [<a href='https://secure.php.net/splfileobject.fwrite'>splfileobject.fwrite</a>]: Write of 7651 bytes failed with errno=28 No space left on device [CORE/src/Cache/Engine/FileEngine.php, line 141]
SplFileObject::fwrite() - [internal], line ??
Cake\Cache\Engine\FileEngine::set() - CORE/src/Cache/Engine/FileEngine.php, line 141
Cake\I18n\TranslatorRegistry::get() - CORE/src/I18n/TranslatorRegistry.php, line 206
Cake\I18n\I18n::getTranslator() - CORE/src/I18n/I18n.php, line 148
__ - CORE/src/I18n/functions.php, line 45
App\Controller\NewsController::view() - APP/Controller/NewsController.php, line 3420
Cake\Controller\Controller::invokeAction() - CORE/src/Controller/Controller.php, line 539
Cake\Controller\ControllerFactory::handle() - CORE/src/Controller/ControllerFactory.php, line 140
Cake\Controller\ControllerFactory::invoke() - CORE/src/Controller/ControllerFactory.php, line 115
Cake\Http\BaseApplication::handle() - CORE/src/Http/BaseApplication.php, line 317
Cake\Http\Runner::handle() - CORE/src/Http/Runner.php, line 77
Cake\Http\Middleware\CsrfProtectionMiddleware::process() - CORE/src/Http/Middleware/CsrfProtectionMiddleware.php, line 164
Cake\Http\Runner::handle() - CORE/src/Http/Runner.php, line 73
Cake\I18n\Middleware\LocaleSelectorMiddleware::process() - CORE/src/I18n/Middleware/LocaleSelectorMiddleware.php, line 61
Cake\Http\Runner::handle() - CORE/src/Http/Runner.php, line 73
Cake\Http\Middleware\BodyParserMiddleware::process() - CORE/src/Http/Middleware/BodyParserMiddleware.php, line 157
Cake\Http\Runner::handle() - CORE/src/Http/Runner.php, line 73
Notice: file_put_contents() [function.file-put-contents]: Write of 2559 bytes failed with errno=28 No space left on device in /www/wwwroot/www.adminso.com/vendor/cakephp/cakephp/src/Log/Engine/FileLog.php on line 140
Notice (8): SplFileObject::fwrite() [<a href='https://secure.php.net/splfileobject.fwrite'>splfileobject.fwrite</a>]: Write of 5131 bytes failed with errno=28 No space left on device [CORE/src/Cache/Engine/FileEngine.php, line 141]
SplFileObject::fwrite() - [internal], line ??
Cake\Cache\Engine\FileEngine::set() - CORE/src/Cache/Engine/FileEngine.php, line 141
Cake\Database\Schema\CachedCollection::describe() - CORE/src/Database/Schema/CachedCollection.php, line 85
Cake\ORM\Table::getSchema() - CORE/src/ORM/Table.php, line 513
Cake\ORM\Query::addDefaultTypes() - CORE/src/ORM/Query.php, line 290
Cake\ORM\Query::__construct() - CORE/src/ORM/Query.php, line 184
Cake\ORM\Table::query() - CORE/src/ORM/Table.php, line 1702
Cake\ORM\Table::find() - CORE/src/ORM/Table.php, line 1263
App\Controller\NewsController::action_() - APP/Controller/NewsController.php, line 6433
App\Controller\NewsController::get_data() - APP/Controller/NewsController.php, line 5701
App\Controller\NewsController::action_cache() - APP/Controller/NewsController.php, line 5625
App\Controller\NewsController::cache_action() - APP/Controller/NewsController.php, line 5281
App\Controller\NewsController::view() - APP/Controller/NewsController.php, line 3436
Cake\Controller\Controller::invokeAction() - CORE/src/Controller/Controller.php, line 539
Cake\Controller\ControllerFactory::handle() - CORE/src/Controller/ControllerFactory.php, line 140
Cake\Controller\ControllerFactory::invoke() - CORE/src/Controller/ControllerFactory.php, line 115
Cake\Http\BaseApplication::handle() - CORE/src/Http/BaseApplication.php, line 317
Notice: file_put_contents() [function.file-put-contents]: Write of 3151 bytes failed with errno=28 No space left on device in /www/wwwroot/www.adminso.com/vendor/cakephp/cakephp/src/Log/Engine/FileLog.php on line 140
Notice (8): SplFileObject::fwrite() [<a href='https://secure.php.net/splfileobject.fwrite'>splfileobject.fwrite</a>]: Write of 920 bytes failed with errno=28 No space left on device [CORE/src/Cache/Engine/FileEngine.php, line 141]
SplFileObject::fwrite() - [internal], line ??
Cake\Cache\Engine\FileEngine::set() - CORE/src/Cache/Engine/FileEngine.php, line 141
Cake\Database\Schema\CachedCollection::describe() - CORE/src/Database/Schema/CachedCollection.php, line 85
Cake\ORM\Table::getSchema() - CORE/src/ORM/Table.php, line 513
Cake\ORM\Query::addDefaultTypes() - CORE/src/ORM/Query.php, line 290
Cake\ORM\Query::__construct() - CORE/src/ORM/Query.php, line 184
Cake\ORM\Table::query() - CORE/src/ORM/Table.php, line 1702
Cake\ORM\Table::find() - CORE/src/ORM/Table.php, line 1263
App\Controller\NewsController::action_() - APP/Controller/NewsController.php, line 6539
App\Controller\NewsController::get_data() - APP/Controller/NewsController.php, line 5701
App\Controller\NewsController::action_cache() - APP/Controller/NewsController.php, line 5625
App\Controller\NewsController::cache_action() - APP/Controller/NewsController.php, line 5281
App\Controller\NewsController::view() - APP/Controller/NewsController.php, line 3436
Cake\Controller\Controller::invokeAction() - CORE/src/Controller/Controller.php, line 539
Cake\Controller\ControllerFactory::handle() - CORE/src/Controller/ControllerFactory.php, line 140
Cake\Controller\ControllerFactory::invoke() - CORE/src/Controller/ControllerFactory.php, line 115
Cake\Http\BaseApplication::handle() - CORE/src/Http/BaseApplication.php, line 317
Notice: file_put_contents() [function.file-put-contents]: Write of 3150 bytes failed with errno=28 No space left on device in /www/wwwroot/www.adminso.com/vendor/cakephp/cakephp/src/Log/Engine/FileLog.php on line 140
Notice (8): SplFileObject::fwrite() [<a href='https://secure.php.net/splfileobject.fwrite'>splfileobject.fwrite</a>]: Write of 185 bytes failed with errno=28 No space left on device [CORE/src/Cache/Engine/FileEngine.php, line 141]
SplFileObject::fwrite() - [internal], line ??
Cake\Cache\Engine\FileEngine::set() - CORE/src/Cache/Engine/FileEngine.php, line 141
Cake\Cache\Cache::write() - CORE/src/Cache/Cache.php, line 266
App\Controller\NewsController::action_() - APP/Controller/NewsController.php, line 6766
App\Controller\NewsController::get_data() - APP/Controller/NewsController.php, line 5701
App\Controller\NewsController::action_cache() - APP/Controller/NewsController.php, line 5625
App\Controller\NewsController::cache_action() - APP/Controller/NewsController.php, line 5281
App\Controller\NewsController::view() - APP/Controller/NewsController.php, line 3634
Cake\Controller\Controller::invokeAction() - CORE/src/Controller/Controller.php, line 539
Cake\Controller\ControllerFactory::handle() - CORE/src/Controller/ControllerFactory.php, line 140
Cake\Controller\ControllerFactory::invoke() - CORE/src/Controller/ControllerFactory.php, line 115
Cake\Http\BaseApplication::handle() - CORE/src/Http/BaseApplication.php, line 317
Cake\Http\Runner::handle() - CORE/src/Http/Runner.php, line 77
Cake\Http\Middleware\CsrfProtectionMiddleware::process() - CORE/src/Http/Middleware/CsrfProtectionMiddleware.php, line 164
Cake\Http\Runner::handle() - CORE/src/Http/Runner.php, line 73
Cake\I18n\Middleware\LocaleSelectorMiddleware::process() - CORE/src/I18n/Middleware/LocaleSelectorMiddleware.php, line 61
Cake\Http\Runner::handle() - CORE/src/Http/Runner.php, line 73
Notice: file_put_contents() [function.file-put-contents]: Write of 2790 bytes failed with errno=28 No space left on device in /www/wwwroot/www.adminso.com/vendor/cakephp/cakephp/src/Log/Engine/FileLog.php on line 140
Warning (512): long cache was unable to write '7d8fb29bb067cac156385ea48fe03781' to Cake\Cache\Engine\FileEngine cache [CORE/src/Cache/Cache.php, line 275]
Cake\Cache\Cache::write() - CORE/src/Cache/Cache.php, line 275
App\Controller\NewsController::action_() - APP/Controller/NewsController.php, line 6766
App\Controller\NewsController::get_data() - APP/Controller/NewsController.php, line 5701
App\Controller\NewsController::action_cache() - APP/Controller/NewsController.php, line 5625
App\Controller\NewsController::cache_action() - APP/Controller/NewsController.php, line 5281
App\Controller\NewsController::view() - APP/Controller/NewsController.php, line 3634
Cake\Controller\Controller::invokeAction() - CORE/src/Controller/Controller.php, line 539
Cake\Controller\ControllerFactory::handle() - CORE/src/Controller/ControllerFactory.php, line 140
Cake\Controller\ControllerFactory::invoke() - CORE/src/Controller/ControllerFactory.php, line 115
Cake\Http\BaseApplication::handle() - CORE/src/Http/BaseApplication.php, line 317
Cake\Http\Runner::handle() - CORE/src/Http/Runner.php, line 77
Cake\Http\Middleware\CsrfProtectionMiddleware::process() - CORE/src/Http/Middleware/CsrfProtectionMiddleware.php, line 164
Cake\Http\Runner::handle() - CORE/src/Http/Runner.php, line 73
Cake\I18n\Middleware\LocaleSelectorMiddleware::process() - CORE/src/I18n/Middleware/LocaleSelectorMiddleware.php, line 61
Cake\Http\Runner::handle() - CORE/src/Http/Runner.php, line 73
Cake\Http\Middleware\BodyParserMiddleware::process() - CORE/src/Http/Middleware/BodyParserMiddleware.php, line 157
Notice: file_put_contents() [function.file-put-contents]: Write of 2585 bytes failed with errno=28 No space left on device in /www/wwwroot/www.adminso.com/vendor/cakephp/cakephp/src/Log/Engine/FileLog.php on line 140
Notice (8): SplFileObject::fwrite() [<a href='https://secure.php.net/splfileobject.fwrite'>splfileobject.fwrite</a>]: Write of 155 bytes failed with errno=28 No space left on device [CORE/src/Cache/Engine/FileEngine.php, line 141]
SplFileObject::fwrite() - [internal], line ??
Cake\Cache\Engine\FileEngine::set() - CORE/src/Cache/Engine/FileEngine.php, line 141
Cake\Cache\Cache::write() - CORE/src/Cache/Cache.php, line 266
App\Controller\NewsController::action_() - APP/Controller/NewsController.php, line 6766
App\Controller\NewsController::get_data() - APP/Controller/NewsController.php, line 5701
App\Controller\NewsController::action_cache() - APP/Controller/NewsController.php, line 5625
App\Controller\NewsController::cache_action() - APP/Controller/NewsController.php, line 5281
App\Controller\NewsController::view() - APP/Controller/NewsController.php, line 3663
Cake\Controller\Controller::invokeAction() - CORE/src/Controller/Controller.php, line 539
Cake\Controller\ControllerFactory::handle() - CORE/src/Controller/ControllerFactory.php, line 140
Cake\Controller\ControllerFactory::invoke() - CORE/src/Controller/ControllerFactory.php, line 115
Cake\Http\BaseApplication::handle() - CORE/src/Http/BaseApplication.php, line 317
Cake\Http\Runner::handle() - CORE/src/Http/Runner.php, line 77
Cake\Http\Middleware\CsrfProtectionMiddleware::process() - CORE/src/Http/Middleware/CsrfProtectionMiddleware.php, line 164
Cake\Http\Runner::handle() - CORE/src/Http/Runner.php, line 73
Cake\I18n\Middleware\LocaleSelectorMiddleware::process() - CORE/src/I18n/Middleware/LocaleSelectorMiddleware.php, line 61
Cake\Http\Runner::handle() - CORE/src/Http/Runner.php, line 73
Notice: file_put_contents() [function.file-put-contents]: Write of 2790 bytes failed with errno=28 No space left on device in /www/wwwroot/www.adminso.com/vendor/cakephp/cakephp/src/Log/Engine/FileLog.php on line 140
Warning (512): long cache was unable to write '5ad9cafb82de8caf3682df2c6b0b6351' to Cake\Cache\Engine\FileEngine cache [CORE/src/Cache/Cache.php, line 275]
Cake\Cache\Cache::write() - CORE/src/Cache/Cache.php, line 275
App\Controller\NewsController::action_() - APP/Controller/NewsController.php, line 6766
App\Controller\NewsController::get_data() - APP/Controller/NewsController.php, line 5701
App\Controller\NewsController::action_cache() - APP/Controller/NewsController.php, line 5625
App\Controller\NewsController::cache_action() - APP/Controller/NewsController.php, line 5281
App\Controller\NewsController::view() - APP/Controller/NewsController.php, line 3663
Cake\Controller\Controller::invokeAction() - CORE/src/Controller/Controller.php, line 539
Cake\Controller\ControllerFactory::handle() - CORE/src/Controller/ControllerFactory.php, line 140
Cake\Controller\ControllerFactory::invoke() - CORE/src/Controller/ControllerFactory.php, line 115
Cake\Http\BaseApplication::handle() - CORE/src/Http/BaseApplication.php, line 317
Cake\Http\Runner::handle() - CORE/src/Http/Runner.php, line 77
Cake\Http\Middleware\CsrfProtectionMiddleware::process() - CORE/src/Http/Middleware/CsrfProtectionMiddleware.php, line 164
Cake\Http\Runner::handle() - CORE/src/Http/Runner.php, line 73
Cake\I18n\Middleware\LocaleSelectorMiddleware::process() - CORE/src/I18n/Middleware/LocaleSelectorMiddleware.php, line 61
Cake\Http\Runner::handle() - CORE/src/Http/Runner.php, line 73
Cake\Http\Middleware\BodyParserMiddleware::process() - CORE/src/Http/Middleware/BodyParserMiddleware.php, line 157
Notice: file_put_contents() [function.file-put-contents]: Write of 2585 bytes failed with errno=28 No space left on device in /www/wwwroot/www.adminso.com/vendor/cakephp/cakephp/src/Log/Engine/FileLog.php on line 140
Notice (8): SplFileObject::fwrite() [<a href='https://secure.php.net/splfileobject.fwrite'>splfileobject.fwrite</a>]: Write of 2492 bytes failed with errno=28 No space left on device [CORE/src/Cache/Engine/FileEngine.php, line 141]
SplFileObject::fwrite() - [internal], line ??
Cake\Cache\Engine\FileEngine::set() - CORE/src/Cache/Engine/FileEngine.php, line 141
Cake\Cache\Cache::write() - CORE/src/Cache/Cache.php, line 266
App\Controller\NewsController::action_() - APP/Controller/NewsController.php, line 6766
App\Controller\NewsController::get_data() - APP/Controller/NewsController.php, line 5701
App\Controller\NewsController::action_cache() - APP/Controller/NewsController.php, line 5493
App\Controller\NewsController::cache_action() - APP/Controller/NewsController.php, line 5281
App\Controller\NewsController::view() - APP/Controller/NewsController.php, line 3698
Cake\Controller\Controller::invokeAction() - CORE/src/Controller/Controller.php, line 539
Cake\Controller\ControllerFactory::handle() - CORE/src/Controller/ControllerFactory.php, line 140
Cake\Controller\ControllerFactory::invoke() - CORE/src/Controller/ControllerFactory.php, line 115
Cake\Http\BaseApplication::handle() - CORE/src/Http/BaseApplication.php, line 317
Cake\Http\Runner::handle() - CORE/src/Http/Runner.php, line 77
Cake\Http\Middleware\CsrfProtectionMiddleware::process() - CORE/src/Http/Middleware/CsrfProtectionMiddleware.php, line 164
Cake\Http\Runner::handle() - CORE/src/Http/Runner.php, line 73
Cake\I18n\Middleware\LocaleSelectorMiddleware::process() - CORE/src/I18n/Middleware/LocaleSelectorMiddleware.php, line 61
Cake\Http\Runner::handle() - CORE/src/Http/Runner.php, line 73
Notice: file_put_contents() [function.file-put-contents]: Write of 2791 bytes failed with errno=28 No space left on device in /www/wwwroot/www.adminso.com/vendor/cakephp/cakephp/src/Log/Engine/FileLog.php on line 140
Notice (8): unserialize() [<a href='https://secure.php.net/function.unserialize'>function.unserialize</a>]: Error at offset 4041 of 4085 bytes [APP/Controller/NewsController.php, line 5571]
unserialize - [internal], line ??
App\Controller\NewsController::action_cache() - APP/Controller/NewsController.php, line 5571
App\Controller\NewsController::cache_action() - APP/Controller/NewsController.php, line 5281
App\Controller\NewsController::article_show() - APP/Controller/NewsController.php, line 4290
App\Controller\NewsController::view() - APP/Controller/NewsController.php, line 3822
Cake\Controller\Controller::invokeAction() - CORE/src/Controller/Controller.php, line 539
Cake\Controller\ControllerFactory::handle() - CORE/src/Controller/ControllerFactory.php, line 140
Cake\Controller\ControllerFactory::invoke() - CORE/src/Controller/ControllerFactory.php, line 115
Cake\Http\BaseApplication::handle() - CORE/src/Http/BaseApplication.php, line 317
Cake\Http\Runner::handle() - CORE/src/Http/Runner.php, line 77
Cake\Http\Middleware\CsrfProtectionMiddleware::process() - CORE/src/Http/Middleware/CsrfProtectionMiddleware.php, line 164
Cake\Http\Runner::handle() - CORE/src/Http/Runner.php, line 73
Cake\I18n\Middleware\LocaleSelectorMiddleware::process() - CORE/src/I18n/Middleware/LocaleSelectorMiddleware.php, line 61
Cake\Http\Runner::handle() - CORE/src/Http/Runner.php, line 73
Cake\Http\Middleware\BodyParserMiddleware::process() - CORE/src/Http/Middleware/BodyParserMiddleware.php, line 157
Cake\Http\Runner::handle() - CORE/src/Http/Runner.php, line 73
Cake\Routing\Middleware\RoutingMiddleware::process() - CORE/src/Routing/Middleware/RoutingMiddleware.php, line 161
Notice: file_put_contents() [function.file-put-contents]: Write of 2487 bytes failed with errno=28 No space left on device in /www/wwwroot/www.adminso.com/vendor/cakephp/cakephp/src/Log/Engine/FileLog.php on line 140
Notice (8): unserialize() [<a href='https://secure.php.net/function.unserialize'>function.unserialize</a>]: Error at offset 12273 of 12277 bytes [APP/Controller/NewsController.php, line 5571]
unserialize - [internal], line ??
App\Controller\NewsController::action_cache() - APP/Controller/NewsController.php, line 5571
App\Controller\NewsController::cache_action() - APP/Controller/NewsController.php, line 5281
App\Controller\NewsController::article_show() - APP/Controller/NewsController.php, line 4310
App\Controller\NewsController::view() - APP/Controller/NewsController.php, line 3822
Cake\Controller\Controller::invokeAction() - CORE/src/Controller/Controller.php, line 539
Cake\Controller\ControllerFactory::handle() - CORE/src/Controller/ControllerFactory.php, line 140
Cake\Controller\ControllerFactory::invoke() - CORE/src/Controller/ControllerFactory.php, line 115
Cake\Http\BaseApplication::handle() - CORE/src/Http/BaseApplication.php, line 317
Cake\Http\Runner::handle() - CORE/src/Http/Runner.php, line 77
Cake\Http\Middleware\CsrfProtectionMiddleware::process() - CORE/src/Http/Middleware/CsrfProtectionMiddleware.php, line 164
Cake\Http\Runner::handle() - CORE/src/Http/Runner.php, line 73
Cake\I18n\Middleware\LocaleSelectorMiddleware::process() - CORE/src/I18n/Middleware/LocaleSelectorMiddleware.php, line 61
Cake\Http\Runner::handle() - CORE/src/Http/Runner.php, line 73
Cake\Http\Middleware\BodyParserMiddleware::process() - CORE/src/Http/Middleware/BodyParserMiddleware.php, line 157
Cake\Http\Runner::handle() - CORE/src/Http/Runner.php, line 73
Cake\Routing\Middleware\RoutingMiddleware::process() - CORE/src/Routing/Middleware/RoutingMiddleware.php, line 161
Notice: file_put_contents() [function.file-put-contents]: Write of 2489 bytes failed with errno=28 No space left on device in /www/wwwroot/www.adminso.com/vendor/cakephp/cakephp/src/Log/Engine/FileLog.php on line 140 Specializing in chip design, Nvidia launches a customized version of the big language model ChipNeMo! - AdminSo
Xinzhiyuan ReportEditor: So sleepyIntroduction to New Intelligence ElementNvidia: The big language model may fully support the entire chip design process!At the recently opened ICCAD2023 conference, the NVIDIA team demonstrated the use of AI models to test chips, which attracted industry attention.As is well known, semiconductor design is a highly challenging task
Introduction to New Intelligence ElementNvidia: The big language model may fully support the entire chipdesign process!
At the recently opened ICCAD2023 conference, the NVIDIA team demonstrated the use of AI models to test chips, which attracted industry attention.
As is well known, semiconductor design is a highly challenging task.
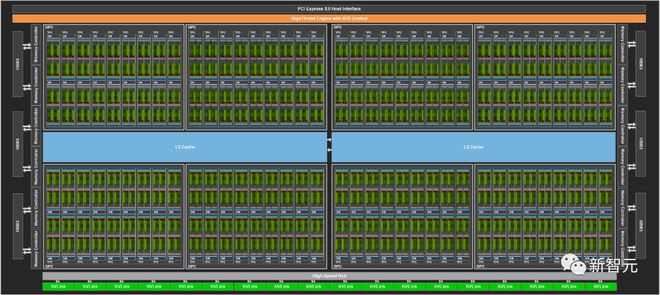
Under a microscope, top-notch chips such as the Nvidia H100 look like a carefully planned metropolis, with billions of transistors connected to streets ten thousand times thinner than hair.
To build such a digital giant city, multiple engineering teams need to collaborate for up to two years.
Among them, some teams are responsible for determining the overall architecture of the chip, some teams are responsible for producing and placing various ultra small circuits, and some teams are responsible for testing. Each task requires specialized methods, software programs, and computer languages.
ChipNeMo: Nvidia Version of the "Chip Design" Big Model
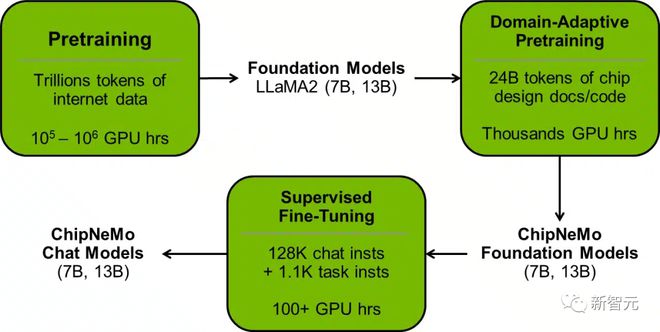
Recently, a research team from NVIDIA developed a custom LLM called ChipNeMo, which is trained based on internal company data for generating and optimizing software, and providing assistance to human designers.
Paper address: https://research.nvidia.com/publication/2023-10_chipnemo-domain-adapted-llms-chip-design
Researchers did not directly deploy ready-made commercial or open-source LLMs, but instead adopted the following domain adaptation technologies: custom word breakers, domain adaptive continuous pre training (DAPT), supervised fine-tuning with domain specific instructions (SFT), and domain adapted retrieval models.
Not only did it achieve similar or better performance in a series of design tasks, but it also reduced the size of the model by up to five times (the customized ChipNeMo model only had 13 billion parameters).
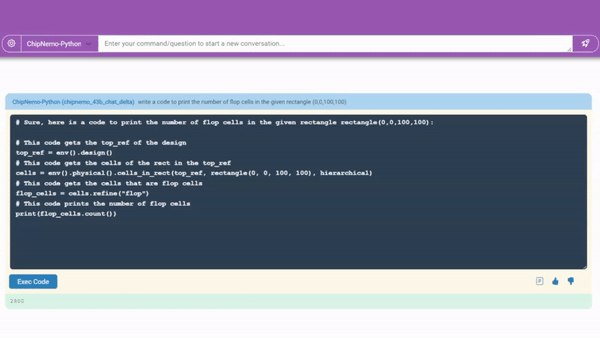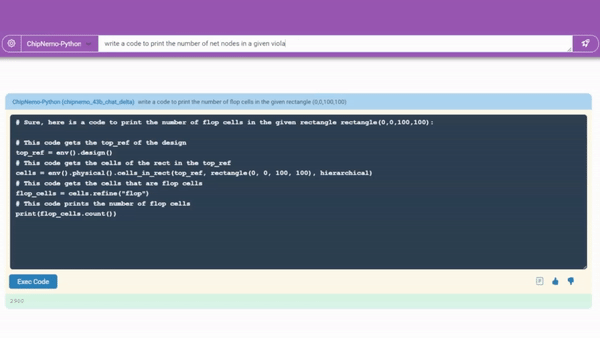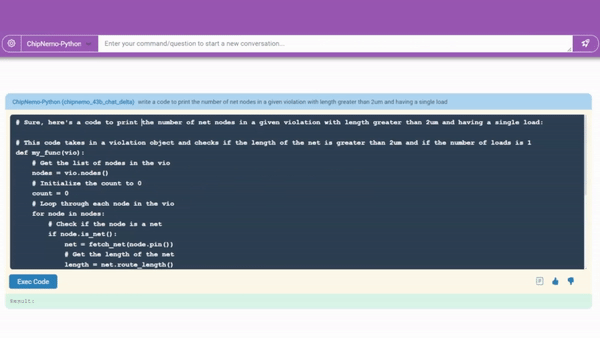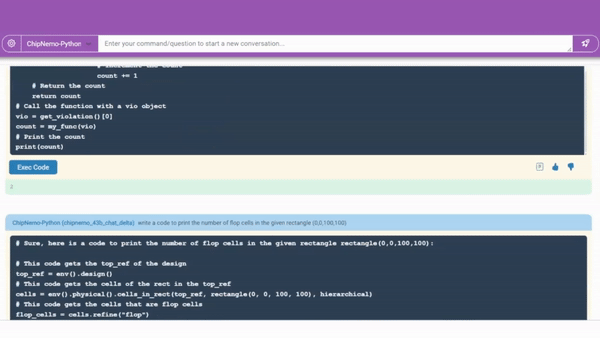
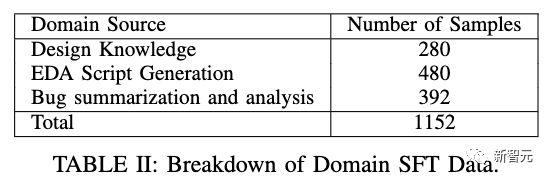
Specifically, researchers evaluated three chip design applications: engineering assistant chat robots, EDA script generation, and error summary and analysis.
Among them, chat robots can answer various questions about GPU architecture and design, and help many engineers quickly find technical documents.
The code generator can now create approximately 10-20 lines of code fragments using two commonly used professional languages for chip design.
Code generator
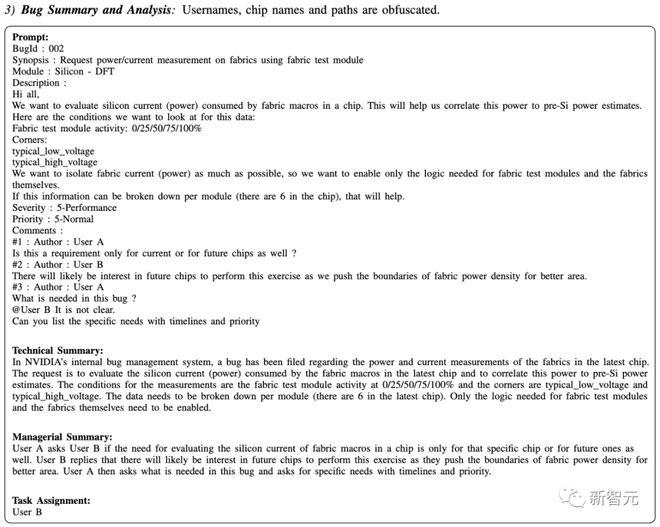
And the most popular analysis tool can automatically complete the time-consuming task of maintaining and updating error descriptions.
In response, Bill Dally, the chief scientist of NVIDIA, stated that even if we only increased productivity by 5%, it would be a huge victory.
ChipNeMo is an important first step taken by LLM in the field of complex semiconductor design.
This also means that for highly specialized fields, useful generative AI models can be trained using their internal data.
data
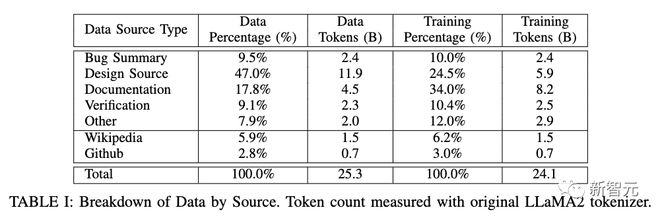
trainDAPTdatadatadata
datatrain231token
dataLlama2traindataDAPT
In the code section, the focus is on programming languages related to chip design in GitHub, such as C++, Python, and Verilog.
(SFT) SFTdatadata
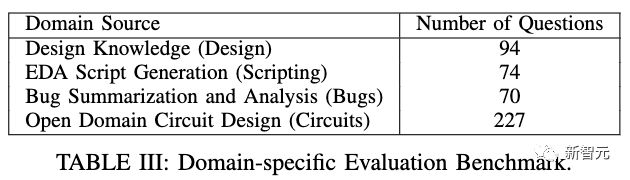
In order to quickly and quantitatively evaluate the accuracy of various models, researchers have also constructed a specialized evaluation standard - AutoEval, which is similar to the multi choice questions used in MMLU.
train
ChipNeModatadatatrain
traindatadatatrain/
datatrain
After DAPT, supervised fine-tuning (SFT) is further utilized to achieve model alignment.
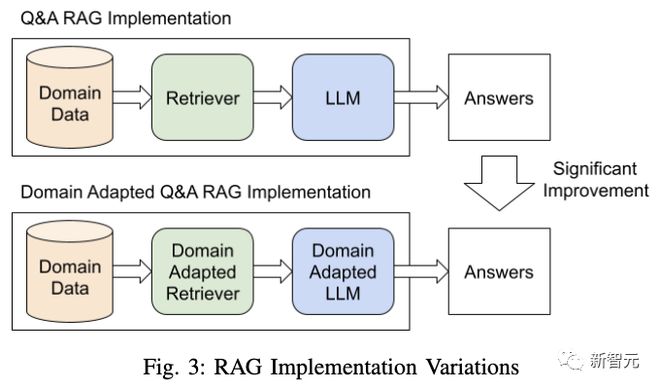
Researchers have chosen the retrieval augmentation generation (RAG) method to address the illusion problem of large models.
Researchers have found that using domain specific language models in RAG can significantly improve the quality of answers to domain specific questions.
traindatatrain
result
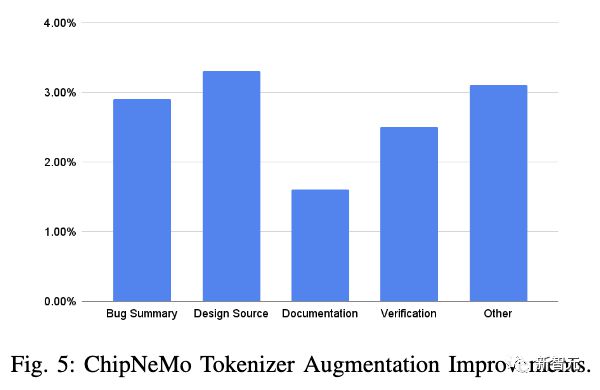
data1.6%3.3%
ChipNeMoAutoEvalresult
The accuracy of the DAPT model on open field academic benchmarks has slightly decreased.
2. DAPT has had a positive impact on the tasks of the field itself. Among them, the knowledge level of the model in internal design and circuit design has significantly improved.
3. result
4. The improvement of tasks within the domain by DAPT is positively correlated with the size of the model, and larger models have a more significant improvement in task performance in specific domains after DAPT.
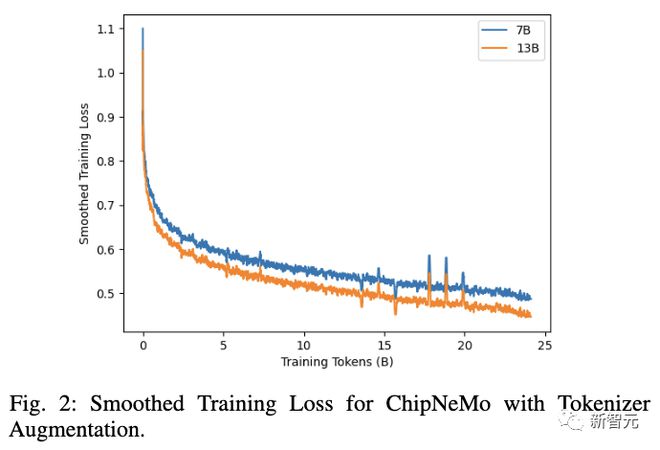
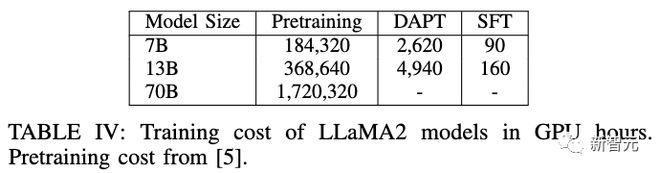
128A100 GPUtrainChipNeMotrain
DAPTtrain1.5%
RAG and Engineering Assistant Chat Robot
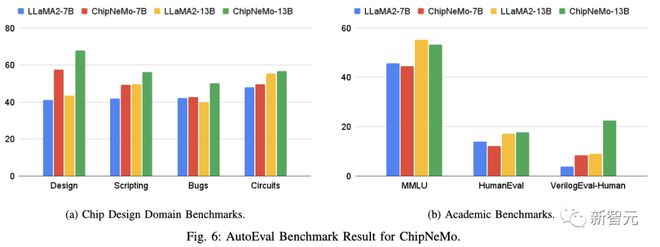
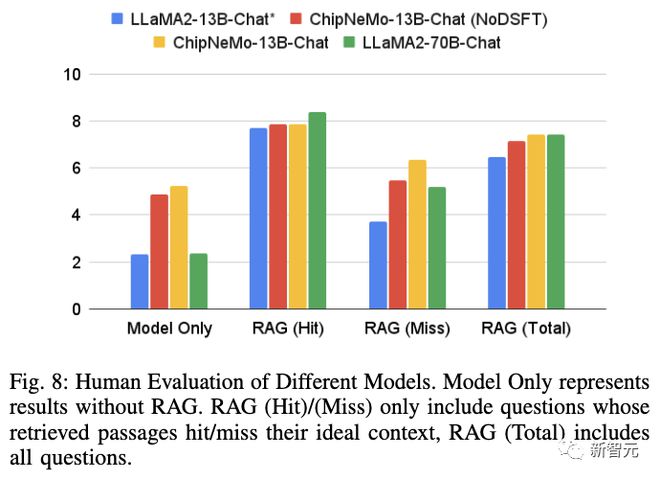
RAGChipNeMoLlama 2result8
-RAG can significantly improve the model's score, and even if RAG misses, the score is usually higher.
-ChipNeMo-13B-Chat obtained higher scores than similar sized Llama2-13B-Chat.
-ChipNeMo-13B-Chat using RAG achieved the same score (7.4) as Llama2-70B-Chat using RAG. When RAG hits, Llama2-70B-Chat scores higher; But when RAG misses, ChipNeMo with domain adaptation performs better.
-The field SFT improved the performance of ChipNeMo-13B-Chat by 0.28 (with RAG) and 0.33 (without RAG).
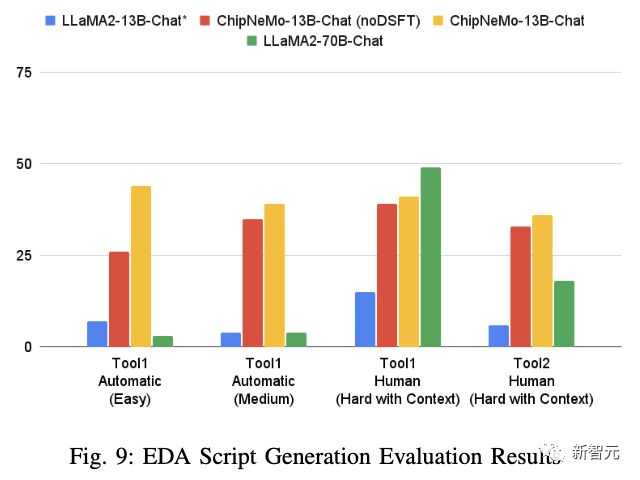
EDA script generation
9DAPTAPISFTresult
resultLLaMA2-70BPythontrainTcl
And this also highlights the advantages of DAPT in niche or proprietary programming languages.
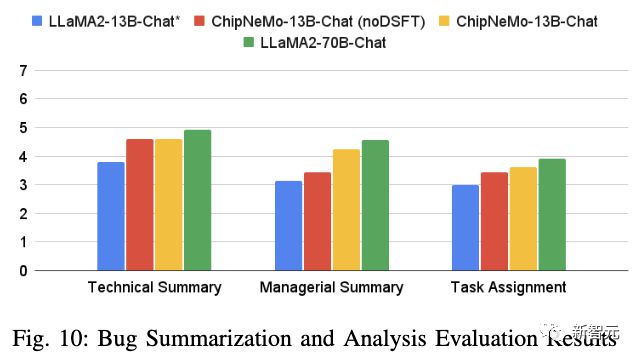
In addition, the domain SFT has significantly improved the performance of the model in managing summary and task allocation.
However, the Llama2-70B-Chat model performs better than ChipNeMo-13B in all tasks.
Although larger Llama270B can sometimes achieve accuracy similar to ChipNeMo, as shown in Figures 8, 9, and 10. But it is equally important to consider the cost-effectiveness of smaller models.
For example, unlike Llama270B, Nvidia's ChipNeMo13B can be directly loaded into a single A100GPU of graphics memory without any quantization required. This greatly improves the inference speed of the model. At the same time, relevant research has also shown that the inference cost of the 8B model is 8-12 times lower than that of the 62B model.
Therefore, when deciding whether to use a larger general model or a smaller specialized model in a production environment, the following criteria must be considered:
- train
Smaller domain adaptation models can be compared to larger universal models. Although domain adaptation may incur additional upfront costs, using smaller models can significantly reduce operational costs.
-Unique features of use cases:
From Figures 6, 9, and 10, it can be seen that the domain adaptation model performs extremely well in tasks that rarely appear in the public domain, such as writing code in proprietary languages or libraries. For general large models, even with carefully selected contexts, it is difficult to match the accuracy of domain adaptation models in such situations.
- data
traindatatraintoken
-Diversity of use cases:
Although general models can be fine-tuned for specific tasks, domain adaptation models can be applied to various tasks in the domain.
Disclaimer: The content of this article is sourced from the internet. The copyright of the text, images, and other materials belongs to the original author. The platform reprints the materials for the purpose of conveying more information. The content of the article is for reference and learning only, and should not be used for commercial purposes. If it infringes on your legitimate rights and interests, please contact us promptly and we will handle it as soon as possible! We respect copyright and are committed to protecting it. Thank you for sharing.